
Introduction to Gitlab CI/CD
This article presents some of the possibilities that GitLab CI/CD offers. You will find on the Codelabs platform two tutorials linked to this article, which will show you two use cases.

CQRS, which means Command Query Responsibility Segregation, comes from CQS (Command Query Separation) introduced by Bertrand Meyer in Object Oriented Software Construction. Meyer states that every method should be either a query or a command.
The difference between CQS and CQRS is that every CQRS object is divided in two objects: one for the query and one for the command.
A command is defined as a method that changes state. On the contrary, a query only returns a value.
The following schema shows a basic implementation of the CQRS pattern inside an application. All messages are sent through commands and events. Let's take a closer look at this.
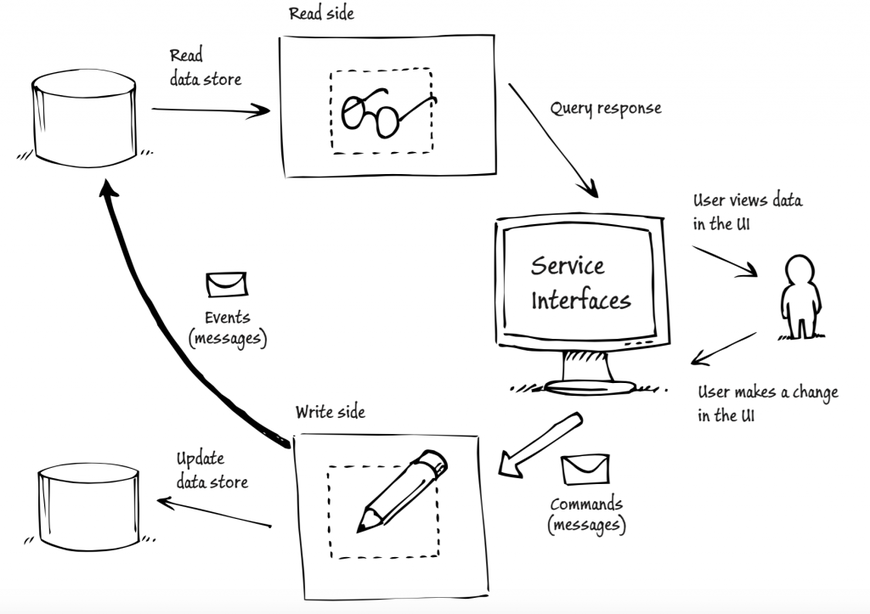 Example of implementation of CQRS pattern
Example of implementation of CQRS pattern
We can clearly see the separation between writing parts and reading ones: the user does a modification on his page, resulting in a command being executed. Once this command is fully handled, an event is dispatched to signal a modification.
A command tells our application to do something. Its name always uses the indicative tense, like TerminateBusiness or SendForgottenPasswordEmail. It's very important not to confine these names to create, change, delete... and to really focus on the use cases (see CQRS Documents at the end of this document for more information).
A command captures the intent of the user. No content in the response is returned by the server, only queries are in charge of retrieving data.
Using different data stores in our application for the command and query parts seems to be a very interesting idea. As Udi Dahan explains very well in his article Clarified CQRS, we could create a user interface oriented database, which would reflect what we need to display to our user. We would gain in both performance and speed. Dissociating our data stores (one for the modification of data and one for reading) does not imply the use of relational databases for both of them for instance. Therefore, it would be more thoughtful to use a database that can read our queries fastly.
If we separate our data sources, how can we still make them synchronized? Indeed, our "read" data store is not supposed to be aware that a command has been sent! This is where events come into play.
An event is a notification of something that has happened. Like a command, an event must respect a rule regarding names. Indeed, the name of an event always needs to be in the past tense, because we need to notify other parties listening on our event that a command has been completed. For instance, UserRegistered is a valid event name. Events are processed by one or more consumers. Those consumers are in charge of keeping things synchronized in our query store.
Very much like commands, events are messages. The difference with a command is summed up here: a command is characterized by an action that must happen, and an event by something that has happened.
The different benefits from this segregation are numerous. Here are a few:
One of the main con is to convince the members of a team that its benefits justify the additional complexity of this solution, as underlines the excellent article called CQRS Journey (see below).
The CQRS pattern must be used inside a bounded context (key notion of Domain Driven Development), or a business component of your application. Indeed, although this pattern has an impact on your code at several places, it must not be at the higher level of your application.
What's interesting with CQRS is event sourcing. It can be used without application of the CQRS pattern, but if we use CQRS, event sourcing appears like a must-have. Event sourcing consists in saving every event that is occurring, in a database, and therefore having a back-up of facts. In a design of event sourcing, you cannot delete or modify events, you can only add more. This is beneficial for our business and our information system, because we can know at a specific time what is the status of a command, a user or something else. Also, saving events allows us to rebuild the series of events and gain time in analysis. One of the examples given by Greg Young in the conference Code on the Beach, is the balance in a bank account. It can be considered like a column in a table that we update every time money is debited or credited on the account. One other approach would be to store in our database all transactions that enabled us to get to this balance. It then becomes easier to be sure that the indicated amount is correct, because we keep a trace of events that have occurred, without being able to change them.
We will not go into more details on this principle in this article. A very interesting in-depth study is available in the article CQRS Journey (see below).
CQRS is a simple pattern, which enables fantastic possibilities. It consists in separating the reading part from the writing part, with queries and commands.
Many advantages result from its usage, especially in term of flexibility and scaling.
Event sourcing completes theCQRS pattern by saving the history that determines the current state of our application. This is very useful in domains like accounting, because you get in your database a series of events (like financial transactions for instance) that cannot be modified or deleted.
CQRS Documents, Greg Young
CQRS Journey, Dominic Betts, Julián Domínguez, Grigori Melnik, Fernando Simonazzi, Mani Subramanian
Clarified CQRS, Udi Dahan
CQRS and Event Sourcing - Code on the Beach 2014, Greg Young
Author(s)
Romain Pierlot
Diplomé de l'ISEP en 2013, Romain Pierlot est ingénieur en Etudes et Développement chez Eleven Labs, avec qui il s'amuse comme un petit fou.
You wanna know more about something in particular?
Let's plan a meeting!
Our experts answer all your questions.
Contact usDiscover other content about the same topic
This article presents some of the possibilities that GitLab CI/CD offers. You will find on the Codelabs platform two tutorials linked to this article, which will show you two use cases.

Are you suffering from domain anemia? Let's look at what an anemic domain model is and how things can change.
Today I'd like to talk about a tool that will allow us to rapidly isolate an incorrect commit, that caused a bug in our application: git bisect