
Installer et configurer Caddy 2 avec certificat SSL pour tous vos sous-domaines
Sécuriser votre serveur avec des certificat SSL pour tous vos sous-domaines grâce au DNS challenge

Apache Iceberg est un format de table ouvert pour les données volumineuses, conçu pour résoudre les problèmes de performance et de fiabilité des formats traditionnels comme Apache Hive. Il offre une approche moderne pour gérer les métadonnées de tables, permettant des opérations ACID, la gestion des versions et des performances optimisées pour les requêtes analytiques.
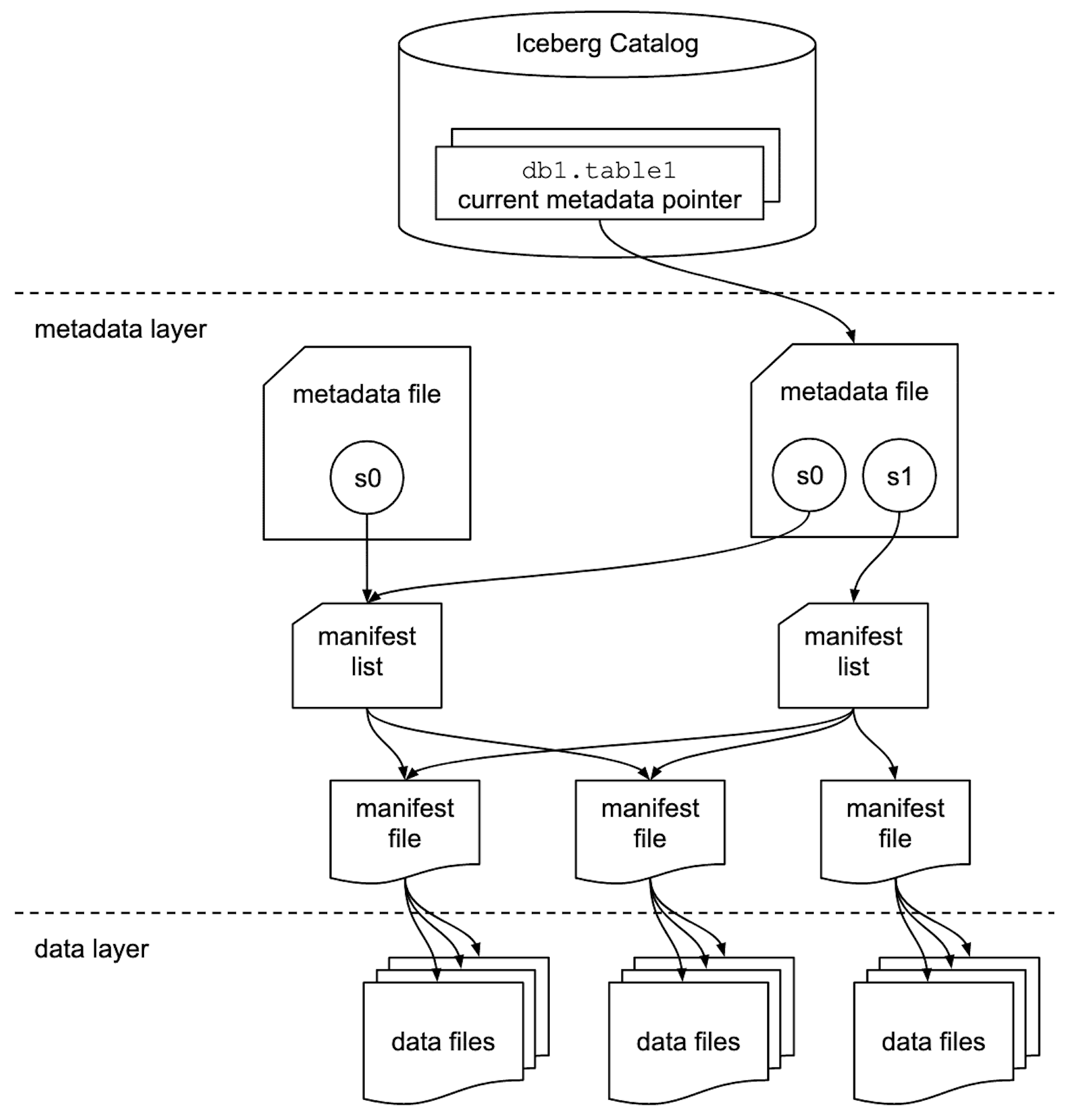
Apache Iceberg utilise une architecture hiérarchique de métadonnées composée de trois niveaux principaux pour gérer efficacement les données :
Point d'entrée qui maintient la liste des tables et leurs emplacements. Il peut être implémenté via différents backends comme AWS Glue, Apache Hive Metastore, ou des bases de données relationnelles.
Les données réelles sont stockées dans des fichiers Parquet, ORC, ou Avro, organisés selon la structure de partitionnement définie dans les métadonnées. Ces fichiers contiennent :
Les fichiers constituent la couche de stockage effective des données, tandis que les manifest files et table metadata permettent de les localiser et de les interroger efficacement. Dans la suite, nous choisirons le format Parquet comme type de fichiers. En effet il s'agit du format par défaut lors de l'utilisation de Iceberg. Néanmoins le format de fichier contenant les données est modifiable via ce paramètre : write.format.default.
Cette architecture métadonnées-centrée d'Iceberg apporte plusieurs bénéfices spécifiques aux fichiers Parquet :
Iceberg maintient un historique complet des modifications via un système de snapshots. Chaque modification (INSERT, UPDATE, DELETE) crée un nouveau snapshot sans affecter les précédents, permettant ainsi le time travel et la lecture cohérente des données.
Le format intègre plusieurs mécanismes d'optimisation :
Après avoir exploré les fondements et avantages d'Apache Iceberg, il est pertinent de se pencher sur son déploiement concret dans un environnement cloud.
AWS propose une suite de services compatibles avec Apache Iceberg, facilitant son intégration à grande échelle dans des architectures data modernes. Voici comment Iceberg peut être mis en œuvre efficacement dans cet écosystème.
AWS Glue Data Catalog sert de catalog Iceberg natif, offrant une intégration transparente avec l'écosystème AWS. Il gère automatiquement les métadonnées et assure la compatibilité avec les services AWS comme Amazon Athena, Amazon EMR et AWS Glue ETL.
AWS S3 constitue le backend de stockage idéal pour Iceberg sur AWS, offrant :
AWS S3 Tables une nouvelle classe de stockage managée pour Iceberg. Les tables Amazon S3 sont jusqu’à 3 fois plus rapides par rapport aux tables Iceberg non gérées, et peuvent supporter jusqu’à 10 fois plus de transactions par seconde par rapport aux tables Iceberg stockées dans des compartiments S3 à usage général.
Côté services, plusieurs outils AWS viennent enrichir l’exploitation des tables Iceberg :
Maintenant que les concepts clés et l’intégration d’Iceberg dans un environnement cloud comme AWS ont été abordés, voyons comment cela se traduit concrètement sur le terrain.
Pour mieux comprendre ce format de table, nous allons utiliser Spark (PySpark) afin de manipuler des données et explorer ses capacités.
Reprenons le code de notre précédent article rédigé par Thierry T. Démarrer avec Apache Spark étape par étape.
Ici afin d'explorer les différentes fonctionnalités du format Iceberg, nous utiliserons la configuration suivante:
Catalog : Base de données relationnelle en JDBC avec SQLite dans un fichier nommé : mydb
Stockage : Un bucket S3 grâce à MinIO sur Docker nous servira d'espace de stockage. Grâce au docker file ci dessous et à la commande suivante :
docker compose up -d
Nous allons crée un bucket S3 nommé : local-bucket. On pourra s'y connecter via l'UI en se rendant sur notre navigateur à l'url suivante : http://localhost:9001/ et ainsi s'identifier avec le user et password suivant : MyUserTest1
version: "3.9" name: iceberg-bucket services: minio: image: minio/minio command: server /data --console-address ":9001" environment: MINIO_ROOT_USER: MyUserTest1 MINIO_ROOT_PASSWORD: MyUserTest1 ports: - "9000:9000" - "9001:9001" volumes: - minio_data:/data createbuckets: image: quay.io/minio/mc:RELEASE.2025-03-12T17-29-24Z depends_on: - minio restart: on-failure entrypoint: > /bin/sh -c " sleep 5; /usr/bin/mc alias set dockerminio http://minio:9000 MyUserTest1 MyUserTest1; /usr/bin/mc mb dockerminio/local-bucket; exit 0; " volumes: minio_data:
Spark : Voici comment la session spark est définie (version 3.5.6):
from pyspark.sql import SparkSession S3_BUCKET_NAME = "local-bucket" MINIO_ROOT_USER = MINIO_ROOT_PASSWORD = "MyUserTest1" spark = ( SparkSession.builder.appName("Iceberg4Lakehouse") .config( "spark.jars.packages", "org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.9.1,org.apache.iceberg:iceberg-aws-bundle:1.4.0,org.xerial:sqlite-jdbc:3.46.0.0", ) .config( "spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions", ) .config( "spark.sql.catalog.local_catalog", "org.apache.iceberg.spark.SparkCatalog" ) .config( "spark.sql.catalog.local_catalog.catalog-impl", "org.apache.iceberg.jdbc.JdbcCatalog", ) .config( "spark.sql.catalog.local_catalog.io-impl", "org.apache.iceberg.aws.s3.S3FileIO", ) .config( "spark.sql.catalog.local_catalog.uri", "jdbc:sqlite:file:mydb", ) .config( "spark.sql.catalog.local_catalog.warehouse", f"s3a://{S3_BUCKET_NAME}/DATA", ) .config( "spark.sql.catalog.local_catalog.s3.endpoint", "http://localhost:9000", ) .config("spark.sql.catalog.local_catalog.s3.access-key-id", MINIO_ROOT_USER) .config("spark.sql.catalog.local_catalog.s3.secret-access-key", MINIO_ROOT_PASSWORD) .config("spark.sql.catalog.local_catalog.s3.path-style-access", "true") .config("spark.sql.catalog.local_catalog.drop-table-include-data", "true") .config("spark.sql.iceberg.check-ordering", "false") .config("spark.sql.catalog.local_catalog.jdbc.schema-version", "V1") .getOrCreate() )
Maintenant que les bases sont posées, voyons concrètement comment interagir avec une table Iceberg à travers différentes opérations, telles que l’insertion de données, la mise à jour, ou encore la gestion de l’évolution du schéma.
Avant de manipuler des données, il faut d’abord créer une table Iceberg. Celle-ci peut être définie à l’aide d’une simple requête SQL, avec le schéma de colonnes souhaité et le format de stockage approprié ou directement à partir d'un dataframe spark. Voici un exemple de création de table avec partitionnement.
df = spark.createDataFrame( [ (1, "Alice", "2023-01-01"), (2, "Bob", "2023-01-02"), (3, "Anna", "2023-01-02"), (4, "Tom", "2023-01-03"), ], ["id", "name", "signup_date"], ) spark.sql("use local_catalog") spark.sql("CREATE DATABASE IF NOT EXISTS db") df.writeTo("db.signup").partitionedBy("signup_date").createOrReplace() spark.read.format("iceberg").load("db.signup").orderBy("id").show()
+---+-----+-----------+ | id| name|signup_date| +---+-----+-----------+ | 1|Alice| 2023-01-01| | 2| Bob| 2023-01-02| | 3| Anna| 2023-01-02| | 4| Tom| 2023-01-03| +---+-----+-----------+
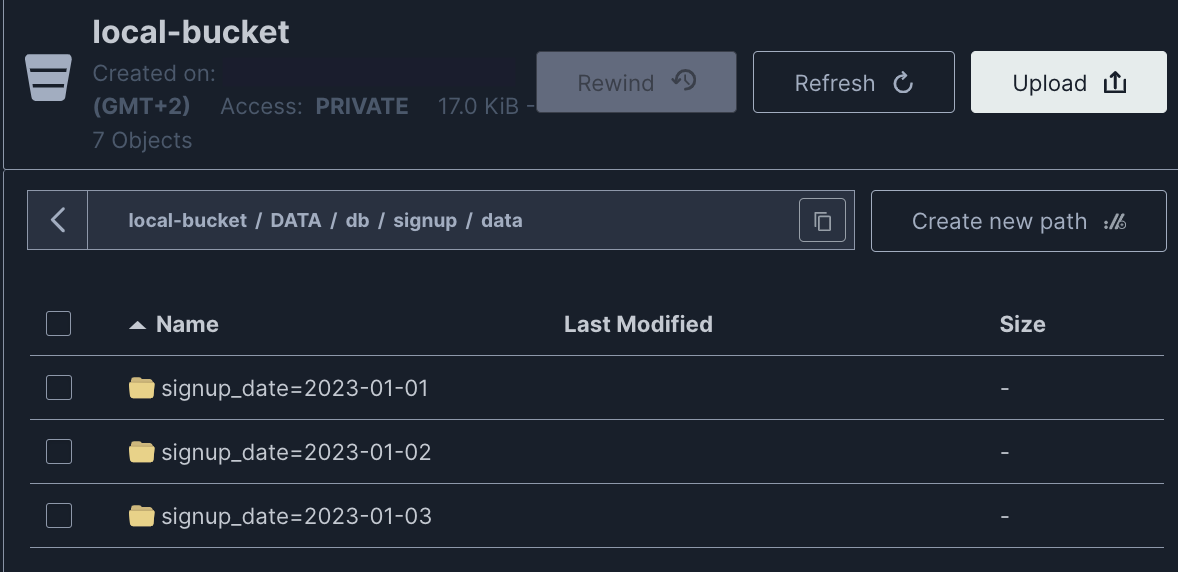
En se connectant à la console Minio au chemin suivant: local-bucket/DATA/db/signup/data. On voit bien dans l'espace de stockage que les données sont physiquement partitionnés par date.
Une fois la table créée, on peut y insérer des données. Apache Iceberg supporte l’insertion, ce qui permet d’ajouter de nouvelles lignes de manière simple et transactionnelle, même dans un environnement distribué.
df_new = spark.createDataFrame( [ (5, "Sarah", "2023-01-04"), (6, "Mike", "2023-01-04"), (7, "Tony", "2023-01-04"), ], ["id", "name", "signup_date"], ) # Insertion simple avec append df_new.writeTo("db.signup").append() spark.read.format("iceberg").load("db.signup").orderBy("id").show()
+---+-----+-----------+ | id| name|signup_date| +---+-----+-----------+ | 1|Alice| 2023-01-01| | 2| Bob| 2023-01-02| | 3| Anna| 2023-01-02| | 4| Tom| 2023-01-03| | 5|Sarah| 2023-01-04| | 6| Mike| 2023-01-04| | 7| Tony| 2023-01-04| +---+-----+-----------+
Apache Iceberg prend également en charge l’instruction MERGE INTO, qui permet de réaliser des opérations de type upsert.
Un upsert est une combinaison de deux opérations : update (mise à jour) et insert (insertion). Si la donnée existe déjà (selon une condition), elle est mise à jour ; sinon, elle est insérée.
C’est une opération particulièrement utile pour intégrer des flux de données incrémentales ou faire de la synchronisation avec des sources externes.
# Cette stratégie combine mise à jour et insertion : # Données mixtes (mises à jour + nouveaux enregistrements) df_mixed = spark.createDataFrame( [ (1, "Alice Johnson", "2023-01-01"), # Mise à jour (7, "Emma", "2023-01-05"), # Nouveau (8, "David", "2023-01-05"), # Nouveau ], ["id", "name", "signup_date"], ).createOrReplaceTempView("df_mixed") spark.sql( """ MERGE INTO db.signup AS target USING df_mixed AS source ON target.id = source.id WHEN MATCHED THEN UPDATE SET * WHEN NOT MATCHED THEN INSERT * """ ) spark.read.format("iceberg").load("db.signup").orderBy("id").show()
+---+-------------+-----------+ | id| name|signup_date| +---+-------------+-----------+ | 1|Alice Johnson| 2023-01-01| | 2| Bob| 2023-01-02| | 3| Anna| 2023-01-02| | 4| Tom| 2023-01-03| | 5| Sarah| 2023-01-04| | 6| Mike| 2023-01-04| | 7| Emma| 2023-01-05| | 8| David| 2023-01-05| +---+-------------+-----------+
L’un des avantages majeurs d’Apache Iceberg est sa capacité à gérer l’évolution de schéma sans interruption. Cela signifie qu’il est possible d’insérer des données contenant de nouvelles colonnes non encore présentes dans la table, sans générer d’erreur. Iceberg ajoutera automatiquement les colonnes manquantes au schéma, tout en conservant les versions précédentes pour garantir la compatibilité et le time travel.
spark.sql( f"ALTER TABLE db.signup SET TBLPROPERTIES ('write.spark.accept-any-schema'='true')" ) df_with_email = spark.createDataFrame( [ (9, "Paul", "2023-01-09", "paul@example.com"), (10, "Marie", "2023-01-09", "marie@example.com"), ], ["id", "name", "signup_date", "email"], ) # Iceberg supporte l'évolution du schéma automatiquement df_with_email.writeTo("db.signup").option("mergeSchema","true").append() spark.read.format("iceberg").load("db.signup").orderBy("id").show()
+---+-------------+-----------+-----------------+ | id| name|signup_date| email| +---+-------------+-----------+-----------------+ | 1|Alice Johnson| 2023-01-01| NULL| | 2| Bob| 2023-01-02| NULL| | 3| Anna| 2023-01-02| NULL| | 4| Tom| 2023-01-03| NULL| | 5| Sarah| 2023-01-04| NULL| | 6| Mike| 2023-01-04| NULL| | 7| Emma| 2023-01-05| NULL| | 8| David| 2023-01-05| NULL| | 9| Paul| 2023-01-09| paul@example.com| | 10| Marie| 2023-01-09|marie@example.com| +---+-------------+-----------+-----------------+
💡NB : Il est également possible de gérer l’évolution du schéma manuellement en ajoutant explicitement les colonnes via une commande ALTER TABLE, avant l’insertion des données :
df_with_last_name = spark.createDataFrame( [ (9, "Paul", "2023-01-09", "paul@example.com", "Derrick"), (10, "Marie", "2023-01-09", "marie@example.com", "Donovan"), ], ["id", "name", "signup_date", "email", "last_name"], ) spark.sql(""" ALTER TABLE db.signup ADD COLUMN last_name STRING """) df_with_last_name.writeTo("db.signup").append() spark.read.format("iceberg").load("db.signup").orderBy("id").show()
---------+--------+-----------+-----------------+---------+ | id| name|signup_date| email|last_name| +---+-------------+-----------+-----------------+---------+ | 1|Alice Johnson| 2023-01-01| NULL| NULL| | 2| Bob| 2023-01-02| NULL| NULL| | 3| Anna| 2023-01-02| NULL| NULL| | 4| Tom| 2023-01-03| NULL| NULL| | 5| Sarah| 2023-01-04| NULL| NULL| | 6| Mike| 2023-01-04| NULL| NULL| | 7| Emma| 2023-01-05| NULL| NULL| | 8| David| 2023-01-05| NULL| NULL| | 9| Paul| 2023-01-09| paul@example.com| NULL| | 10| Marie| 2023-01-09|marie@example.com| NULL| | 11| Jack| 2023-01-09| jack@example.com| Derrick| | 12| Lola| 2023-01-09| lola@example.com| Donovan| +---+-------------+-----------+-----------------+---------+
snapshots_df = spark.sql(f"SELECT * FROM db.signup.snapshots").orderBy( "committed_at", ) snapshots_df.show()
+-------------+-------------------+-------------------+---------+--------------------+--------------------+ | committed_at| snapshot_id| parent_id|operation| manifest_list| summary| +-------------+-------------------+-------------------+---------+--------------------+--------------------+ |2025-... |7759085558406892563| NULL|overwrite|s3a://local-bucke...|{spark.app.id -> ...| |2025-... |8755520537945265641|7759085558406892563| append|s3a://local-bucke...|{spark.app.id -> ...| |2025-... |3147838452100064630|8755520537945265641|overwrite|s3a://local-bucke...|{spark.app.id -> ...| |2025-... |1336414532923420140|3147838452100064630|overwrite|s3a://local-bucke...|{spark.app.id -> ...| |2025-... |9100672136501671111|1336414532923420140| append|s3a://local-bucke...|{spark.app.id -> ...| |2025-... |4524301540483360157|9100672136501671111| append|s3a://local-bucke...|{spark.app.id -> ...| +-------------+-------------------+-------------------+---------+--------------------+--------------------+
first_snapshot_id = snapshots_df.limit(1).collect()[0].snapshot_id spark.read.option("snapshot-id", first_snapshot_id).format("iceberg").load( "db.signup" ).orderBy("id").show()
Nous voici à la première version de la table !
+---+-----+-----------+ | id| name|signup_date| +---+-----+-----------+ | 1|Alice| 2023-01-01| | 2| Bob| 2023-01-02| | 3| Anna| 2023-01-02| | 4| Tom| 2023-01-03| +---+-----+-----------+
Après avoir exploré les fonctionnalités clés et les intégrations possibles avec Apache Iceberg, il est essentiel d’adopter certaines bonnes pratiques pour garantir la performance, la fiabilité et la maintenabilité de vos pipelines de données.
Cette section propose quelques pistes et recommandations pour mieux tirer parti d’Iceberg au quotidien, notamment autour de la gestion des fichiers, l’évolution des schémas, la surveillance et la sécurité. Ces optimisations peuvent contribuer à faciliter le fonctionnement fluide et évolutif de votre architecture data.
Partitionnement optimal
Choisir une stratégie de partitionnement adaptée aux patterns de requêtes les plus fréquents. Éviter le sur-partitionnement qui peut dégrader les performances.
Gestion des petits fichiers
Utiliser régulièrement les opérations de compaction pour éviter l'accumulation de petits fichiers qui dégradent les performances de lecture. La commande suivante lance la compaction des fichiers de données de la table signup, regroupant les petits fichiers en fichiers plus volumineux et plus efficaces à lire.
CALL local_catalog.system.rewrite_data_files(table => 'signup')Maintenance des tables Iceberg
Effectuer régulièrement des opérations de maintenance permet de préserver la performance et la fiabilité des tables Iceberg dans le temps. Cela inclut notamment:
La suppression des snapshots obsolètes à l’aide de la commande expire_snapshots, pour éviter une accumulation inutile de métadonnées.
La purge des fichiers orphelins via remove_orphan_files, afin de libérer de l’espace et de maintenir la cohérence du stockage.
La gestion proactive des métadonnées avec rewrite_manifests, qui permet d’optimiser la structure des fichiers de manifestes, en particulier après de nombreuses insertions ou suppressions.
Sécurité et gouvernance
Implémenter des politiques granulaires (AWS IAM) pour contrôler l'accès aux données et une gouvernance avancée du data lake (grâce à AWS Lake Formation).
Monitoring
Surveiller les métriques de performance pour le tracing des requêtes complexes. Par exemple, Athena peut publier automatiquement les métriques des requêtes dans CloudWatch, ce qui permet :
Apache Iceberg offre une solution robuste pour la gestion des données volumineuses avec des capacités ACID complètes, une évolution de schéma flexible et des performances optimisées. Son intégration native avec l'écosystème AWS en fait un choix idéal pour les architectures de données modernes de type LakeHouse nécessitant fiabilité, scalabilité et performance.
L'adoption d'Iceberg permet de surmonter les limitations des formats traditionnels tout en bénéficiant de la puissance et de la flexibilité des services AWS managés.
Code complet
# main.py from pyspark.sql import SparkSession S3_BUCKET_NAME = "local-bucket" MINIO_ROOT_USER = MINIO_ROOT_PASSWORD = "MyUserTest1" def main(): spark = ( SparkSession.builder.appName("Iceberg4Lakehouse") .config( "spark.jars.packages", "org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.9.1,org.apache.iceberg:iceberg-aws-bundle:1.4.0,org.xerial:sqlite-jdbc:3.46.0.0", ) .config( "spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions", ) .config( "spark.sql.catalog.local_catalog", "org.apache.iceberg.spark.SparkCatalog" ) .config( "spark.sql.catalog.local_catalog.catalog-impl", "org.apache.iceberg.jdbc.JdbcCatalog", ) .config( "spark.sql.catalog.local_catalog.io-impl", "org.apache.iceberg.aws.s3.S3FileIO", ) .config( "spark.sql.catalog.local_catalog.uri", "jdbc:sqlite:file:mydb", ) .config( "spark.sql.catalog.local_catalog.warehouse", f"s3a://{S3_BUCKET_NAME}/DATA", ) .config( "spark.sql.catalog.local_catalog.s3.endpoint", "http://localhost:9000", ) .config("spark.sql.catalog.local_catalog.s3.access-key-id", MINIO_ROOT_USER) .config( "spark.sql.catalog.local_catalog.s3.secret-access-key", MINIO_ROOT_PASSWORD ) .config("spark.sql.catalog.local_catalog.s3.path-style-access", "true") .config("spark.sql.catalog.local_catalog.drop-table-include-data", "true") .config("spark.sql.iceberg.check-ordering", "false") .config("spark.sql.catalog.local_catalog.jdbc.schema-version", "V1") .getOrCreate() ) # 1. Create df = spark.createDataFrame( [ (1, "Alice", "2023-01-01"), (2, "Bob", "2023-01-02"), (3, "Anna", "2023-01-02"), (4, "Tom", "2023-01-03"), ], ["id", "name", "signup_date"], ) spark.sql("use local_catalog") spark.sql("CREATE DATABASE IF NOT EXISTS db") df.writeTo("db.signup").partitionedBy("signup_date").createOrReplace() spark.read.format("iceberg").load("db.signup").orderBy("id").show() # 2. Insert df_new = spark.createDataFrame( [ (5, "Sarah", "2023-01-04"), (6, "Mike", "2023-01-04"), (7, "Tony", "2023-01-04"), ], ["id", "name", "signup_date"], ) # Insertion simple avec append df_new.writeTo("db.signup").append() spark.read.format("iceberg").load("db.signup").orderBy("id").show() # 3. Merge (UPSERT) # Cette stratégie combine mise à jour et insertion : # Données mixtes (mises à jour + nouveaux enregistrements) df_mixed = spark.createDataFrame( [ (1, "Alice Johnson", "2023-01-01"), # Mise à jour (7, "Emma", "2023-01-05"), # Nouveau (8, "David", "2023-01-05"), # Nouveau ], ["id", "name", "signup_date"], ).createOrReplaceTempView("df_mixed") spark.sql( """ MERGE INTO db.signup AS target USING df_mixed AS source ON target.id = source.id WHEN MATCHED THEN UPDATE SET * WHEN NOT MATCHED THEN INSERT * """ ) df_iceberg = spark.read.format("iceberg").load("db.signup") df_iceberg.orderBy("id").show() # 4. Insert avec évolution du schema automatique spark.sql( f"ALTER TABLE db.signup SET TBLPROPERTIES ('write.spark.accept-any-schema'='true')" ) df_with_email = spark.createDataFrame( [ (9, "Paul", "2023-01-09", "paul@example.com"), (10, "Marie", "2023-01-09", "marie@example.com"), ], ["id", "name", "signup_date", "email"], ) # Iceberg supporte l'évolution du schéma automatiquement df_with_email.writeTo("db.signup").option("mergeSchema", "true").append() df_iceberg = spark.read.format("iceberg").load("db.signup").orderBy("id").show() # 5. Insert avec évolution du schema manuelle df_with_last_name = spark.createDataFrame( [ (11, "Jack", "2023-01-09", "jack@example.com", "Derrick"), (12, "Lola", "2023-01-09", "lola@example.com", "Donovan"), ], ["id", "name", "signup_date", "email", "last_name"], ) spark.sql(""" ALTER TABLE db.signup ADD COLUMN last_name STRING """) df_with_last_name.writeTo("db.signup").append() df_iceberg = spark.read.format("iceberg").load("db.signup").orderBy("id").show() # 6. Lister les snapshots snapshots_df = spark.sql(f"SELECT * FROM db.signup.snapshots").orderBy( "committed_at", ) snapshots_df.show() # 7. Lire les données d'un snapshots (time travel) first_snapshot_id = snapshots_df.limit(1).collect()[0].snapshot_id spark.read.option("snapshot-id", first_snapshot_id).format("iceberg").load( "db.signup" ).orderBy("id").show()
version: "3.9" name: iceberg-bucket services: minio: image: minio/minio command: server /data --console-address ":9001" environment: MINIO_ROOT_USER: MyUserTest1 MINIO_ROOT_PASSWORD: MyUserTest1 ports: - "9000:9000" - "9001:9001" volumes: - minio_data:/data createbuckets: image: quay.io/minio/mc:RELEASE.2025-03-12T17-29-24Z depends_on: - minio restart: on-failure entrypoint: > /bin/sh -c " sleep 5; /usr/bin/mc alias set dockerminio http://minio:9000 MyUserTest1 MyUserTest1; /usr/bin/mc mb dockerminio/local-bucket; exit 0; " volumes: minio_data:
Auteur(s)
Adil H.
Data engineer/plumber & AWS specialist
Vous souhaitez en savoir plus sur le sujet ?
Organisons un échange !
Notre équipe d'experts répond à toutes vos questions.
Nous contacterDécouvrez nos autres contenus dans le même thème
Sécuriser votre serveur avec des certificat SSL pour tous vos sous-domaines grâce au DNS challenge

Plongez dans le monde des AST et découvrez comment cette structure de données fondamentale révolutionne le développement moderne.

Retour sur ma première journée de conférences autour de l'IA au Grand Rex à Paris