
Créer un Delta Lake avec Apache Spark
Il existe différents formats de fichier pour stocker la donnée : parquet, avro, csv. Connaissez-vous le format Delta Lake ? Découvrons ensemble les fonctionnalités de ce format.

IPython est un environnement de développement riche pour Python avec des fonctionnalités telles qu'un interpréteur interactif avec de l'auto complétion, un noyau pour Jupyter et du calcul parallélisé.
IPython permet de tester rapidement du code et de voir le résultat immédiatement.
Pour l'installer :
pip install ipython
Ensuite, lancer la commande suivante pour lancer le shell interactif :
ipython
Le shell IPython s'affiche, on peut entrer du code pour qu'il soit lu et évalué par l'interpréteur, puis pour que soit affiché le résultat. Dans cet exemple, je vais saluer wilson :
Python 3.8.10 (default, Mar 15 2022, 12:22:08) Type 'copyright', 'credits' or 'license' for more information IPython 8.3.0 -- An enhanced Interactive Python. Type '?' for help. In [1]: print("Salut wilson !") Salut wilson !
Le résultat s'affiche dessous. Je peux entrer une fonction complète et l'exécuter. En tapant le début du nom de
la fonction, je peux appuyer sur la touche <tab> du clavier pour lancer l'auto-complétion de la fonction.
In [2]: def salut_wilson(): ...: print("Salut Wilson !") ...: In [3]: salut_wilson() Salut Wilson !
IPython a des commandes magiques embarquées, qui facilitent son usage https://ipython.readthedocs.io/en/stable/interactive/magics.html.
Lors du développement d'une application complexe, il y a de nombreux modules à charger avant de pouvoir faire ce que l'on souhaite. Dans une application avec une base de données avec des modèles sqlalchemy, il faut charger les modèles avant de les utiliser.
Pour éviter de le faire à la main à chaque lancement de IPython, il est possible de charger tous les éléments nécessaires et ensuite de lancer le shell interactif.
Dans mon fichier app.py, je mets les imports et les fonctions dont j'ai besoin.
# app.py
import requests # ce module doit être installé dans votre projet : pip install requests
def get_blog_eleven_labs() -> requests.Response:
return requests.get("https://blog.eleven-labs.com")Ensuite, je lance ipython avec le fichier app.py
ipython -i app.py
Ainsi, j'ai accès au module requests pour lancer des requêtes HTTP et à la fonction get_blog_eleven_labs().
% ipython -i app.py Python 3.8.10 (default, Mar 15 2022, 12:22:08) Type 'copyright', 'credits' or 'license' for more information IPython 8.3.0 -- An enhanced Interactive Python. Type '?' for help. In [1]: resp = get_blog_eleven_labs() In [2]: print(resp.status_code) 200 In [3]:
Il n'est pas facile de partager du code produit dans la console IPython. Pour cela, le code sera écrit dans des notebooks Jupyter. C'est un format de fichiers texte qui stocke le contenu d'une cellule et son résultat. Cela permet également de documenter avec du markdown. Ainsi, le code peut être partagé plus facilement avec d'autre personnes.
L'interface Jupyter est quasiment identique à IPython. Il y a des cellules dans laquelle le code est lu, interprété et affiché.
Tout est enregistré dans un fichier .ipynb.
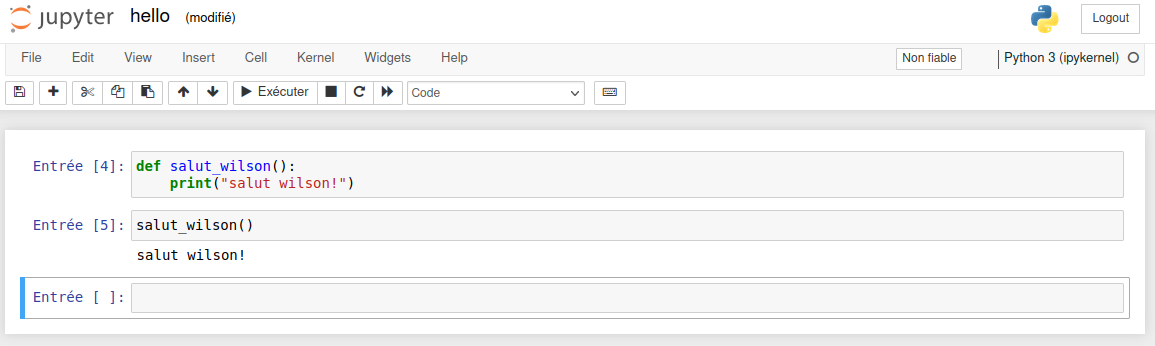
Github met en forme les notebooks Jupyter pour en faciliter la lecture. Par exemple : https://github.com/jdwittenauer/ipython-notebooks/blob/master/notebooks/ml/ML-Exercise1.ipynb
À travers cet article, nous avons fait la découverte d'un shell interactif alternatif : IPython. C'est un outil très utilisé en Python et ses fonctionnalités le rendent plus simple à utiliser par rapport au shell natif. Avec les notebooks Jupyter, le code est plus facilement partagé. Il permet également l'affichage de graphiques pour l'analyse de données. Cette dernière fonctionnalité est très utilisée par les métiers de la data (data analyst, data scientist).
Auteur(s)
Thierry T.
Super Data Boy
Vous souhaitez en savoir plus sur le sujet ?
Organisons un échange !
Notre équipe d'experts répond à toutes vos questions.
Nous contacterDécouvrez nos autres contenus dans le même thème
Il existe différents formats de fichier pour stocker la donnée : parquet, avro, csv. Connaissez-vous le format Delta Lake ? Découvrons ensemble les fonctionnalités de ce format.

Il arrive qu'une fonction ou action ne puisse pas être réalisée à un instant donné. Cela peut être dû à plusieurs facteurs qui ne sont pas maîtrisés. Il est alors possible d'effectuer une nouvelle tentative plus tard. Dans cet article, voyons comment le faire.

Le formatage du code est une source de querelle entre les membres d'une équipe. Résolvons-le une bonne fois pour toute avec le formateur de code Black.