
Créer et implémenter un serveur Model Context Protocol (MCP) en TypeScript
Découvrez comment créer un serveur MCP en TypeScript à l'aide du SDK officiel. Apprenez à fournir un contexte riche aux LLMs.

![]()
ArangoDB est une base de données multi-modèles, ce qui veut dire qu'elle prend en charge plusieurs types de données nativement. Elle supporte les données de type "clé-valeur", "document", "géospatiale" (GeoJSON,..) ainsi que de type "graphe". Toutes ces données peuvent être requêtées avec un seul et même langage, le AQL (ArangoDB Query Language). Le tout en assurant aux transactions les propriétés ACID (atomicité, cohérence, isolation et durabilité).
ArangoDB est open source (Apache License 2.0), possède une édition gratuite "Community", et une autre payante dite "Enterprise" ajoutant des fonctionnalités répondant à des problématiques de projets avancés.
Comme ArangoDB est basé sur des concepts NoSQL, et que tout est en quelque sorte "document" avec une indexation des données customisable et poussée, elle est réputée pour être très réactive sur des opérations écriture/lecture mais également pour des requêtes orientées graphe.
Pour les plus curieux voici un lien vers un benchmark présentant ses résultats avec ceux de bases de données connues et techniquement comparables (ce test ne date pas d'hier, donc à prendre avec des pincettes, mais cela vous donnera une petite idée de ses performances).
ArangoDB vient également avec des notions de réseau et vous laisse choisir entre plusieurs architectures :
"Single instance" : une unique instance Arango existera sur le serveur.
"master/slave" : toutes les opérations se feront sur le "master", pendant que l'instance "slave" effectuera une réplication du "master" de façon asynchrone.
"Active Failover" : presque le même principe "Master/Slave", sauf que l'instance "Master" est déterminée par un composant de la base de données "Agency Supervision" et donne le droit d'écriture et lecture à une instance de façon dynamique.
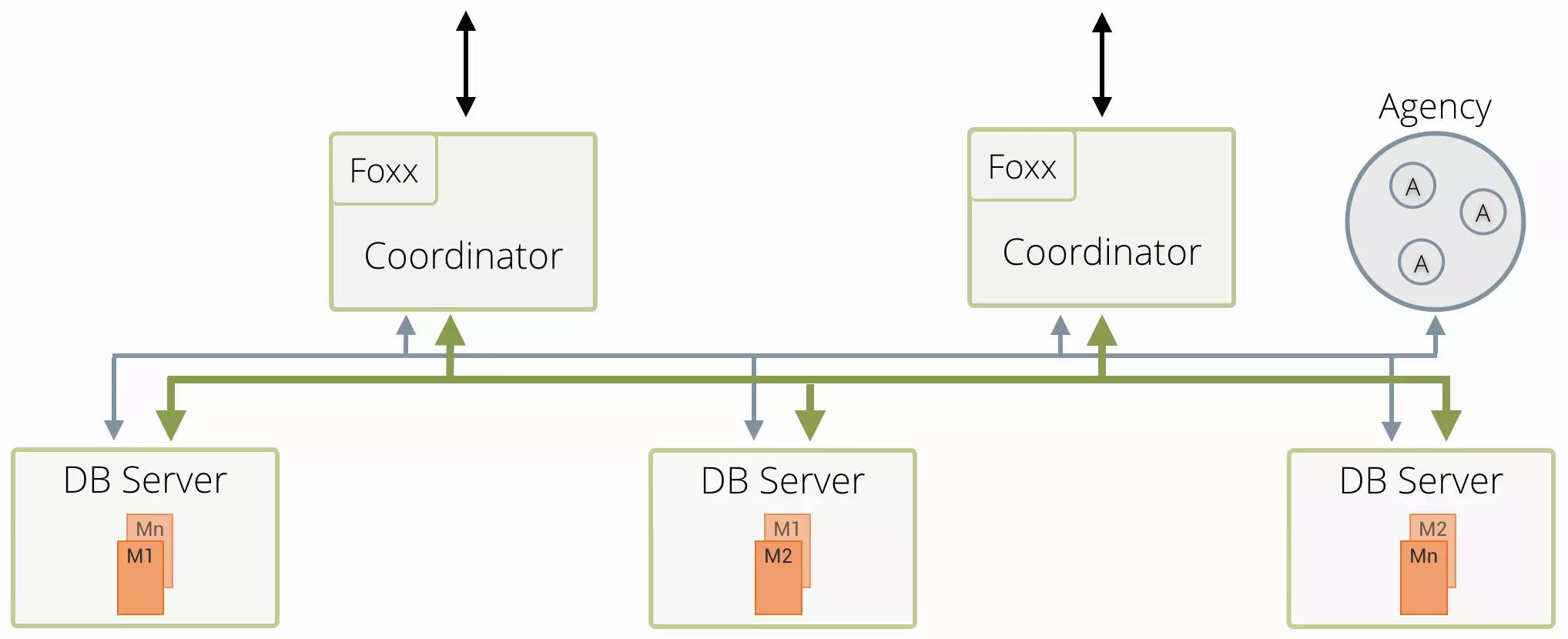
"Cluster" : architecture la plus intéressante selon moi, qui permet une haute scalabilité devant un fort trafic. Chaque "cluster" est composé de différents nœuds ayant des rôles bien définis :
l'Agence (Agency) : elle est en charge de prioriser les opérations qui arrivent et de gérer les services de synchronisation. Sans elle, les composants ci-dessous ne peuvent pas communiquer.
le coordinateur (Coordinator) : ce composant est le point d'entrée entre le client et la donnée, il coordonne les requêtes entre les différentes instances de base de données.
l'instance de base de données (DB Server) : responsable de l'écriture et lecture des données.
Multiples sont les façons d'installer ArangoDB :
Avec ArangoDB Oasis, il est même possible de lancer de façon très simple des instances hautement scalables d'ArangoDB déployées automatiquement sur AWS, Google Cloud ou Azure.
Pour une première prise en main on va faire au plus simple c'est à dire une installation Docker :
docker run -p 8529:8529 -e ARANGO_ROOT_PASSWORD=rocketEleven arangodb/arangodb:3.6.1
Même si Arango de base expose par défaut une API REST pour pouvoir communiquer via le protocole HTTP, une interface graphique est également disponible. Pour nous ce sera à l'adresse http://localhost:8529.
 Le login admin par défaut est "root", et le mot de passe est celui fourni dans la ligne de commande ci-dessus, en l'occurrence "rocketEleven".
Le login admin par défaut est "root", et le mot de passe est celui fourni dans la ligne de commande ci-dessus, en l'occurrence "rocketEleven".
 Chaque serveur a par défaut une base de données "_system", sélectionnez-la.
Chaque serveur a par défaut une base de données "_system", sélectionnez-la.
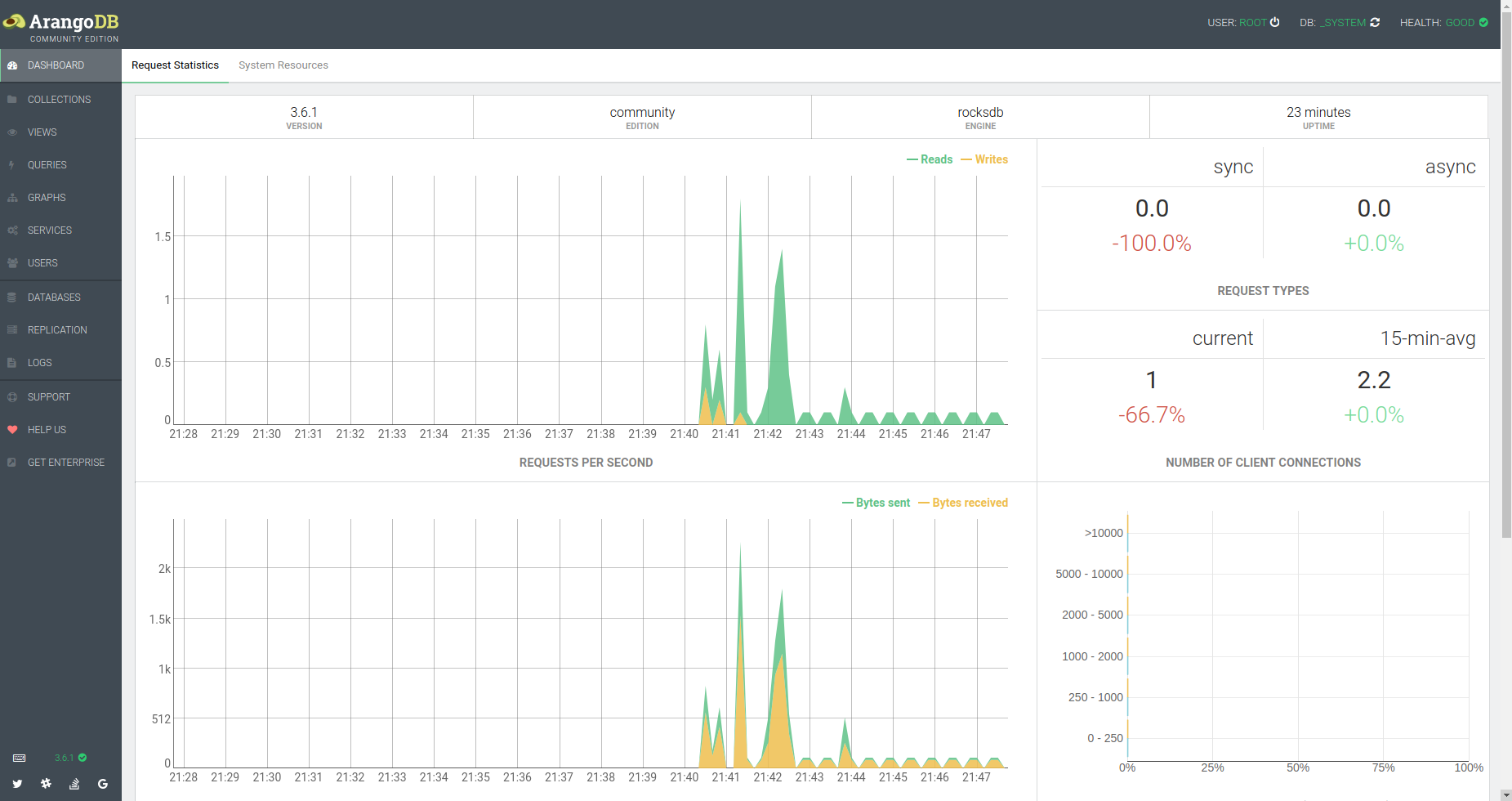
Nous accédons enfin au dashboard de l'instance, qui présente quelques statistiques (le nombre de requêtes par seconde, le type de requête, le nombre de connexions, mémoire, CPU, etc) À savoir que par défaut ArangoDB choisit l'architecture "single instance". Si on avait choisi le mode "cluster" nous aurions eu des statistiques sur les nœuds le composant (Coordinator, DB Server, Agency) ainsi que leurs endpoints.
De cette interface nous pouvons créer des utilisateurs, des nouvelles bases de données, des collections de différents types de données, mais ce sera le sujet de la deuxième partie.
Dans la partie 2 de cet article nous allons voir comment créer une base de données ArongoDB, avec plusieurs collections de différents types de données (Document, Graphe,..) et voir comment les requêter via le language AQL.
Auteur(s)
Victor Delpeyroux
j'aime le back, j'aime le front, et la clarinette
Vous souhaitez en savoir plus sur le sujet ?
Organisons un échange !
Notre équipe d'experts répond à toutes vos questions.
Nous contacterDécouvrez nos autres contenus dans le même thème
Découvrez comment créer un serveur MCP en TypeScript à l'aide du SDK officiel. Apprenez à fournir un contexte riche aux LLMs.

Découvrez comment créer un plugin ESLint en TypeScript avec la nouvelle configuration "flat config" et publiez-le sur npm.

Apprenez à concevoir une barre de recherche accessible pour le web, conforme RGAA. Bonnes pratiques, erreurs fréquentes à éviter et exemples concrets en HTML et React/MUI.