
Nouveau verbe HTTP : QUERY
Vous étiez coincé pour vos recherches volumineuses entre un GET à rallonge ou détourner le POST dans vos APIs, QUERY est là pour répondre à ce besoin

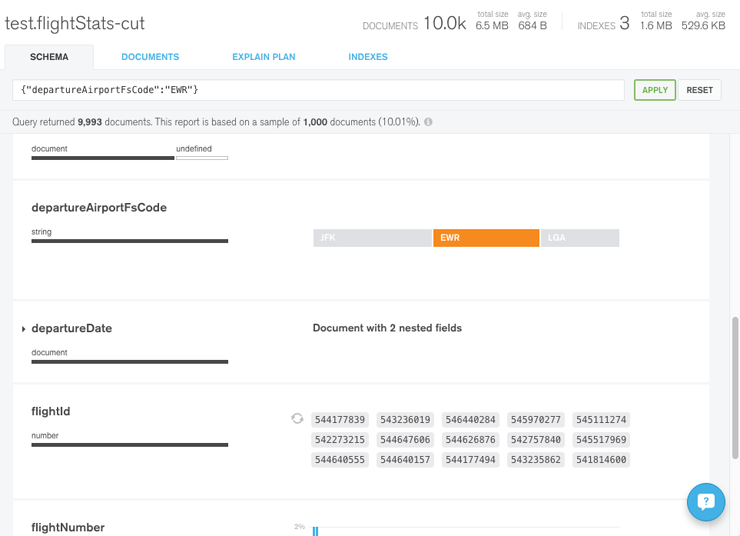
Maintenir une application MongoDB, notamment sur des sujets Datas avec beaucoup de volumétrie et/ou d’opérations peut vite devenir un supplice, surtout si, comme la plupart des Devs, vous n'avez pas accès aux machines de productions qui sont généralement réservées aux exploitants.
Problème : comment trouver dans vos dizaines de millions de données ou requêtes quotidiennes, celles qui ont un impact négatif sur vos performances ou encore les goulots d’étranglement de votre architecture ?
Suite à l’accompagnement de MongoDB inc sur nos sujets Datas au sein de FranceTV Edition Numérique, nous avons automatisé l'utilisation d'outils afin de pouvoir étudier les comportements des productions sans impacts sur les applications.
L'outil, ou plutôt la boite à outils que nous utilisons le plus à ce jour est MTools. Ce projet a été initié et est toujours maintenu par Thomas Rückstieß, ayant travaillé chez... MongoDB :)
Mloginfo lit les log générés par mongoDB et retourne des informations d'utilisation de la base de données. Dans notre cas, ce qui nous intéresse (entre autres) c'est le profiling des requêtes afin de voir celles qui s’exécutent le plus ou encore celles qui consomment le plus de temps.
Exemple d'utilisation :
mloginfo --queries logs.mongo/mongod.log
namespace operation pattern count min (ms) max (ms) mean (ms) 95%-ile (ms) sum (ms)
myCol.$cmd findandmodify {"ID": 1} 916493 101 10486 277 453.0 254423325
myCol.User count {"activeSeg": 1, "updatedAt": 1} 68 30135 1413998 419353 1350776.4 28516024
myCol.InactiveUser count {"inactiveSeg": 1} 32 625038 1019698 813384 984999.6 26028315
Au niveau des colonnes :
Dans notre cas, on peut se rendre compte que la commande "findandmodify" est très souvent utilisée, dans un temps moyen correct. En revanche les fonctions de "count" sont très longues, probablement synonyme d'un index manquant. Plus d'infos ici.
Mlogfilter permet comme son nom l'indique de réduire la quantité d'information d'un fichier de log. Nous pouvons appliquer plusieurs filtres et combiner le résultat avec mloginfo par exemple.
cat logs.mongo/mongod.log | mlogfilter --human --slow --from start +1day
Fri Sep 16 08:01:58.883 I COMMAND [conn195591] command mydb.Client command:
aggregate { aggregate: "Client", pipeline: [ { $match: { somedate:
{ $lte: new Date(1474005604000), $gte: new Date(1469951542000) } } }, { $sort:
{ somedate: -1 } },{ $unwind: "$someArray" }, { $skip: 165000 },
{ $limit: 5000 } ], allowDiskUse: true }
ntoskip:0 keyUpdates:0 writeConflicts:0 numYields:549 reslen:862557
locks:{ Global: { acquireCount: { r: 1120 } },
Database: { acquireCount: { r: 560 } }, Collection: { acquireCount: { r: 560 } } }
protocol:op_query (0hr 0min 3secs 99ms) 3,099ms
Avec cette commande, mlogfilter nous permet de filtrer les logs des commandes les plus longues (--slow) dans un intervalle d'un jour à partir du début du fichier. On peut voir que cela nous donne une commande d'agrégation qui a pris plus de 3 secondes pour s’exécuter.
Plus d'infos sur mlogfilter.
Ces deux exécutables permettent de générer des graphiques afin de visualiser plus d'informations (répartition des appels, type de commandes etc...) de manière graphique.
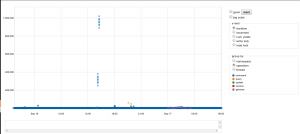
Plus d'infos sur Mlogvis & Mplotqueries.
Mgenerate permet, à partir d'un modèle JSON, de remplir une base de données mongoDB avec de la donnée aléatoire. C'est l'outil parfait pour tester le comportement de fonction ou de requête avec un grand set de données.
Exemple de modèle JSON pour la génération d'une collection User :
{ "user": { "name": { "first": {"$choose": ["Liam", "Noah", "Ethan", "Mason", "Logan", "Jacob", "Lucas", "Jackson", "Aiden", "Jack", "James", "Elijah", "Luke", "William", "Michael", "Alexander", "Oliver", "Owen", "Daniel", "Gabriel", "Henry", "Matthew", "Carter", "Ryan", "Wyatt", "Andrew", "Connor", "Caleb", "Jayden", "Nathan", "Dylan", "Isaac", "Hunter", "Joshua", "Landon", "Samuel", "David", "Sebastian", "Olivia", "Emma", "Sophia", "Ava", "Isabella", "Mia", "Charlotte", "Emily", "Abigail", "Avery", "Harper", "Ella", "Madison", "Amelie", "Lily", "Chloe", "Sofia", "Evelyn", "Hannah", "Addison", "Grace", "Aubrey", "Zoey", "Aria", "Ellie", "Natalie", "Zoe", "Audrey", "Elizabeth", "Scarlett", "Layla", "Victoria", "Brooklyn", "Lucy", "Lillian", "Claire", "Nora", "Riley", "Leah"] }, "last": {"$choose": ["Smith", "Jones", "Williams", "Brown", "Taylor", "Davies", "Wilson", "Evans", "Thomas", "Johnson", "Roberts", "Walker", "Wright", "Robinson", "Thompson", "White", "Hughes", "Edwards", "Green", "Hall", "Wood", "Harris", "Lewis", "Martin", "Jackson", "Clarke", "Clark", "Turner", "Hill", "Scott", "Cooper", "Morris", "Ward", "Moore", "King", "Watson", "Baker" , "Harrison", "Morgan", "Patel", "Young", "Allen", "Mitchell", "James", "Anderson", "Phillips", "Lee", "Bell", "Parker", "Davis"] } }, "gender": {"$choose": ["female", "male"]}, "age": "$number", "address": { "street": {"$string": {"length": 10}}, "house_no": "$number", "zip_code": {"$number": [10000, 99999]}, "city": {"$choose": ["Manhattan", "Brooklyn", "New Jersey", "Queens", "Bronx"]} }, "phone_no": { "$missing" : { "percent" : 30, "ifnot" : {"$number": [1000000000, 9999999999]} } }, "created_at": {"$date": ["2010-01-01", "2014-07-24"] }, "is_active": {"$choose": [true, false]} }, "tags": {"$array": {"of": {"label": "$string", "id": "$oid", "subtags": {"$missing": {"percent": 80, "ifnot": {"$array": ["$string", {"$number": [2, 5]}]}}}}, "number": {"$number": [0, 10] }}} }
Plus d'infos sur Mgenerate.
Mlaunch permet de créer rapidement un environnement local de travail avec mongo. Il peut fournir un configuration MongoDB en stand-alone mais aussi en replica et/ou avec shard. Combiné avec mgenerate, cela peut permettre de mettre en place des environnements de tests très rapidement afin de tester diverses applications tournants sous mongoDB.
Exemple : mlaunch --replicaset --nodes 5
Cette commande permet de demander la création d'une instance mongo avec 5 replicats
est un client lourd permettant d’analyser et de parcourir les données d'une base MongoDB. Globalement l'outils permet de manipuler la data sans réellement demander des compétences en query mongo. Petit bémol, il n'est encore disponible que sous Windows ou MacOs :'(

Auteur(s)
Rémy Jardinet
Architect @ Eleven Labs. Spécialisé dans la Data, l'IOT et les schémas avec des boiboites.
Vous souhaitez en savoir plus sur le sujet ?
Organisons un échange !
Notre équipe d'experts répond à toutes vos questions.
Nous contacterDécouvrez nos autres contenus dans le même thème
Vous étiez coincé pour vos recherches volumineuses entre un GET à rallonge ou détourner le POST dans vos APIs, QUERY est là pour répondre à ce besoin

Sécuriser votre serveur avec des certificat SSL pour tous vos sous-domaines grâce au DNS challenge

Ce guide présente Apache Iceberg, un format de table moderne pour les données volumineuses, la gestion des versions et des performances optimisées.