
Installer et configurer Caddy 2 avec certificat SSL pour tous vos sous-domaines
Sécuriser votre serveur avec des certificat SSL pour tous vos sous-domaines grâce au DNS challenge

Ce mardi 11 Mars 2025, je me suis rendue à l’événement Build with Gemini, une journée de conférences autour de l’IA organisée par Google au Grand Rex à Paris.
Mon utilisation de l’IA avant d’y aller se limitait à des modèles conversationnels comme ChatGPT ou Mistral, ou à des assistants comme Codeium sur mon IDE. J’avais envie de passer au niveau supérieur.

Parmi les conférences que j’ai le plus appréciées, il y a les deux présentées par Matt Cornillon intitulées Entraînez votre propre modèle de reconnaissance de cartes Pokémons, avec Vertex AI et AlloyDB et Discutez avec vos données : créer un chatbot pour jeux de société avec AlloyDB, Gemini et LangChain. On ne va pas se mentir, les titres évidemment geek (quasiment putaclic) m’ont attirée, mais avoir des exemples de cas d’usage concrets sont beaucoup plus pédagogiques.
Matt a su expliquer l’ensemble de sa démarche en utilisant des outils Google, qu’ils soient IA ou non, et d’insister sur l’importance de la data. Dans le cas des cartes Pokémon, la problématique était de pouvoir facilement, en prenant en photo puis en passant ses cartes au fur et à mesure devant une webcam, d’identifier exactement la carte : nom et extension. Grâce à Vertex AI, il a entraîné son propre modèle pour reconnaître une carte une photo (même si maintenant on peut le faire facilement avec Google AI Studio) et l’a couplé avec Cloud Run pour avoir un endpoint accessible.

Pour identifier et comparer sa carte, il a inséré dans une base de données AlloyDB l’ensemble des cartes existantes. Mais comment comparer 2 images ? Pour cela, il leur applique un embedding qui capturent ses caractéristiques essentielles pour créer une représentation vectorielle des données. Dans le cas d’une image, ça sera les bords, formes, motifs, textures, couleurs, etc. Cela donne un vecteur à plusieurs centaines de dimensions qui sera inséré en base de données.
AlloyDB est un fork de Postgresql, et grâce à l’extension pgvector, il est possible de comparer des vecteurs entre eux.
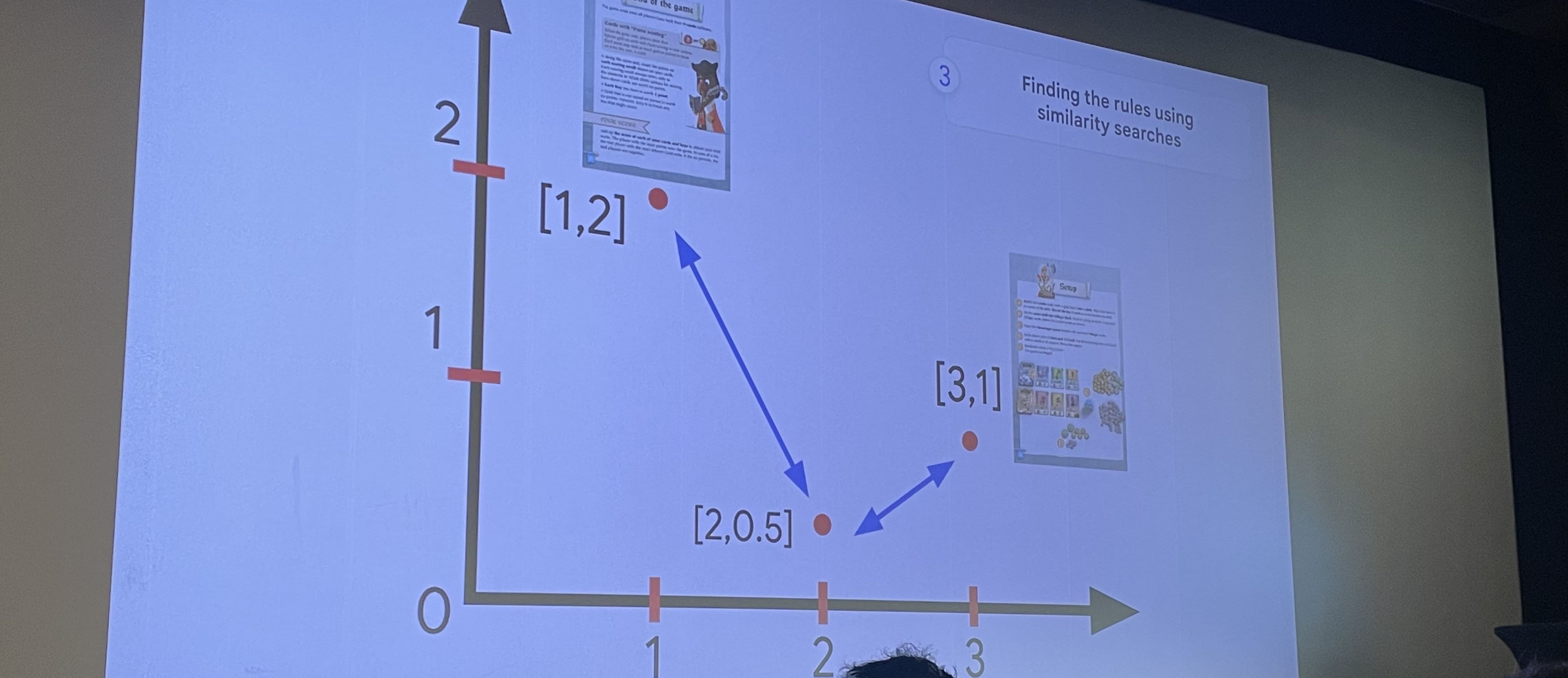
Il existe plusieurs façons de comparer, mais nous allons rester sur celle qui nous intéresse : les images les plus proches que notre propre carte.
ici mettre code SQL

Grâce à toutes ses explications, j’ai envie de faire la même chose pour trier ma collection de timbres.
Sa deuxième conférence apportait de nouveaux outils que je ne connaissais pas comme LangChain qui est un framework pour la création d'applications basées sur LLM, qui peut être considéré comme une orchestrator.
La conférence Plateforme d'IA générative : architecture évolutive et maîtrisée présenté par Didier Girard et Aurélien Pelletier m’a éclairée justement sur plusieurs notions de l’IA, mais aussi comment l’intégrer dans les SI. Ils ont remis l’accent sur l’importance de la data pour avoir une bonne IA, et ont présenté et expliqués les différents éléments qu’on peut trouver dans l’IA et dans son architecture.
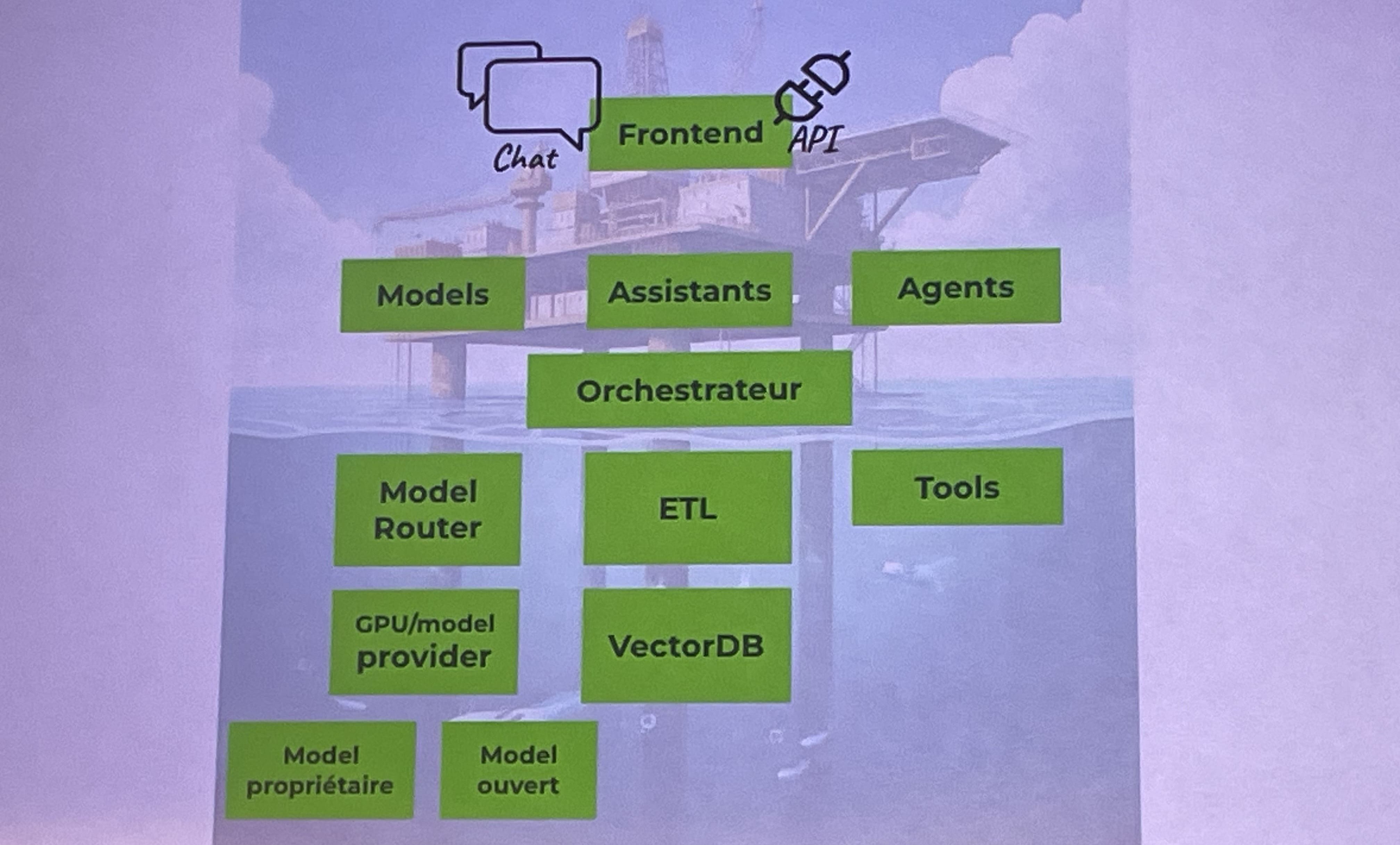
Il existe différents models, avec des coûts et des rapidités de réponse différentes. Il faut mettre en place une achitecture permettant de pouvoir changer de model. Je vais me pencher sur LiteLLM qui a été cité pour les présentateurs.
Pour visualiser ce que ça peut être, pour un développeur, on trouve beaucoup d’assistants pour nous aider sur notre IDE (Codeium, Copilot, etc.) pour “produire” du code plus rapidement. Mais on en trouve de toutes les sortes : pour prendre ses notes et générer des workflows, retranscrire une réunion etc. Pour une entreprise, on peut alimenter son propre assistant les données contextuels internes : grâce à un ochestrator, on va faire passer les données dans un ETL pour ensuite les convertir dans VectorDB.
On peut confondre assistant et agent car parfois on utilise abusivement agent pour assistant : un agent agit, un assistant assiste. Il s’agit d’outil qui vont faire des tâches spécifiques de façon autonome (sans l’humain). Je n’en ai jamais utilisé, mais ils ont cité Smolagents, à tester.
Il s’agit d’outil permettant d’organiser et d’automatiser des processus.
Comme parlé plus haut, il y a LangChain, mais qui serait déjà dépassé par LangGraph.
Conclusion
Cyrena Ramdani a présenté un ensemble d’outils Google pour aider les développeurs dans leurs tâches lors de son talk Coding the future : Comment l'IA générative révolutionne le métier de développeur.
Sans rentrer dans les détails des assistants Google qu’elle a présenté (comme Gemini Code Assist), la réflexion était que ça ne restait que des outils et assistants pour aider des développeurs plus expérimentés à aller plus rapidement sur des tâches avec peu de valeurs ajoutées, pour gagner en productivité.
Cette journée m’a permis de comprendre l’opérationnel autour de l’IA, que ce soit en tant que développeuse ou en tant qu’architecte en me donnant envie d’en apprendre et d’en faire plus !
Auteur(s)
Vous souhaitez en savoir plus sur le sujet ?
Organisons un échange !
Notre équipe d'experts répond à toutes vos questions.
Nous contacterDécouvrez nos autres contenus dans le même thème
Sécuriser votre serveur avec des certificat SSL pour tous vos sous-domaines grâce au DNS challenge

Ce guide présente Apache Iceberg, un format de table moderne pour les données volumineuses, la gestion des versions et des performances optimisées.

Plongez dans le monde des AST et découvrez comment cette structure de données fondamentale révolutionne le développement moderne.