
Installer et configurer Caddy 2 avec certificat SSL pour tous vos sous-domaines
Sécuriser votre serveur avec des certificat SSL pour tous vos sous-domaines grâce au DNS challenge

Pendant presque une décennie, Gitlab a su s'imposer comme forge logicielle, notamment grâce à sa CI (ou Continuous Integration) performante, flexible et facile d'utilisation. Cependant, en fin d'année 2019, Github a lancé sa propre CI/CD avec une intégration unique à la plateforme : les Github Actions.
Dans cet article, nous allons survoler la syntaxe des Github Actions en construisant au fur et à mesure notre premier workflow. Le but de ce dernier sera de valider une modification sur des fichiers Terraform lors d'une pull request (ou PR).
NOTE : je vais utiliser quelques termes qui font référence à Terraform. Leur compréhension n'est pas nécessaire pour comprendre cet article.
Mais avant toute chose, qu'est-ce que la CI/CD ?
Commençons avec une notion indispensable, celle de CI/CD. Tout comme pour notre précédent article Introduction à Gitlab CI, je ne vais pas vous faire une énième définition de ce qu'est la CI/CD mais utiliser à la place deux définitions, de chez Atlassian :
TLDR;
Intégration continue : ensemble de tests et procédures lancées automatiquement à la suite de changements de la base de code.
Déploiement continu : ensemble de procédures lancées automatiquement dans le but de déployer la base de code en production.
L'intégration continue (CI) désigne la pratique qui consiste à automatiser l'intégration des changements de code réalisés par plusieurs contributeurs dans un seul et même projet de développement.
Il s'agit d'une bonne pratique DevOps principale, permettant aux développeurs de logiciels de merger fréquemment des changements de code dans un dépôt central où les builds et les tests s'exécutent ensuite.
Atlassian, https://www.atlassian.com/fr/continuous-delivery/continuous-integration
La livraison continue est une méthode de développement de logiciels dans le cadre de laquelle les modifications de code sont automatiquement préparées en vue de leur publication dans un environnement de production.
Véritable pilier du développement moderne d'applications, la livraison continue étend le principe de l'intégration continue en déployant tous les changements de code dans un environnement de test et/ou de production après l'étape de création.
Lorsque la livraison continue est correctement implémentée, les développeurs disposent en permanence d'un artefact de génération prêt pour le déploiement qui a été soumis avec succès à un processus de test standardisé.
Amazon web services, https://aws.amazon.com/fr/devops/continuous-delivery/
Maintenant que nous nous sommes un peu plus familiarisés avec le concept de CI/CD, il est temps de rentrer dans le vif du sujet !
Comme expliqué précédemment, Github Action est l'outil de CI/CD directement intégré à Github, sorti fin 2019. Là où il fallait avant utiliser des services externes comme Drone.io ou TravisCI pour ne citer qu'eux, Github Action est directement intégré à la plateforme Github.
De plus, du fait de son intégration complète avec Github, il peut également vous aider à automatiser certains de vos workflows directement au sein de Github. La liste des évènements permettant de déclencher un workflow est longue, mais en voici quelques exemples :
Cependant, pour moi, la vraie force des Github Actions provient de son mécanisme de composants réutilisables : les Actions.
Il s'agit de composants logiques, souvent avec du code en amont, permettant d'effectuer certaines tâches. Là où on devait intégrer Terraform dans son image de CI ou l'installer depuis un script, on peut désormais utiliser l'action officielle avec un simple uses: hashicorp/setup-terraform@v1.
Et depuis début Octobre 2021 (voir leur blog post), il est même possible de réutiliser des workflows complet.
On en a souvent parlé dans ce début d'article, mais qu'est-ce qu'un workflow ?
Un workflow est une procédure automatisée composée d'une ou plusieurs étapes. C'est un peu la définition complète de ce que l'on cherche à accomplir écrite en YAML.
La syntaxe de l'objet racine est la suivante :
name : nom du workflow, qui sera également visible sur l'interface Github
(comme dans https://github.com/actions/runner/actions)on : objet contenant les différents déclencheurs du
workflow (liste des évènements disponibles)jobs : définitions du comportement du workflowIl existe d'autres champs, mais nous n'en parlerons pas dans cet article. Cependant, la documentation officielle est relativement bien faite et je vous y invite à la lire pour plus d'informations : https://docs.github.com/en/actions/learn-github-actions/workflow-syntax-for-github-actions
Revenons à notre workflow. Celui-ci devra se déclencher uniquement lorsqu'on crée une PR ou lorsqu'on met à jour ce dernier en rajoutant un nouveau commit.
Pour cela, il faut utiliser le déclencheur pull_request. Par défaut, celui-ci sera lancé lorsqu'on crée la PR (opened), qu'on fait un push dessus (synchronize) ou lorsqu'on rouvre une PR (reopened).
name: Terraform CI on: pull_request: # types: [opened, synchronize, reopened] # valeur par défaut, qu'on peut donc omettre
Maintenant qu'on a determiné quand déclencher le workflow, il est temps d'en venir au corps du workflow : les jobs.
Il faut visualiser un workflow comme un graphe ; nous avons une suite d'actions que l'on appelle un job qui peut en appeller d'autres à la fin de son exécution, qui à leur tour peuvent en exécuter d'autres, jusqu'à ce que l'objectif du workflow soit atteint.
Par exemple, nous pouvons voir notre workflow Terraform CI comme 2 suites d'actions (ou jobs) distinctes :
lint)Pour chacun de ces jobs, il y a quelques champs obligatoires à définir :
runners sont soit des machines fournies par Github soit nos propres machines) (runs-on)steps)Il existe également d'autres champs pour permettre une configuration plus approfondie, dont voici une liste non exhaustive :
name) (bien qu'optionnel, je conseille fortement de quand même de le définir)jobs (needs)if)strategy et concurrency). Ce sont d'ailleurs ces stratégies qui nous permettent d'utiliser ce qu'on appelle des matrices de build (générer plusieurs fois le même job avec un ou plusieurs paramètres changeant)La liste complète est définie dans la documentation.
Concernant notre workflow, découpons un peu ces deux jobs:
lint permettra de valider le format et la syntaxe de nos modifications Terraform. Le plus commun et de faire tourner ces actions sur le runner ubuntu-latest.plan, ça sera un peu plus complexe. On souhaite le faire tourner uniquement si le job lint a réussi. De plus, pour éviter tout problème de concurrence entre deux plan Terraform, il faudrait éviter d'en lancer deux en même temps. Enfin, tout comme le premier, on souhaiterait le lancer sur ubuntu-latestCes besoins se traduisent ainsi :
jobs: lint: name: Format & validate Terraform files runs-on: ubuntu-latest steps: [] plan: name: Generates a speculative execution plan runs-on: ubuntu-latest needs: [lint] # on exécute ce job uniquement si le précédent a réussi concurrency: tf-plan # nous définissons la clé `tf-plan` afin d'éviter de lancer en parallèle tout autre job utilisant cette même clé (ici, le job `plan`) steps: []
Maintenant que nous avons définit comment nos jobs vont être exécuté, il est temps de définir ce qu'ils vont exécuter au travers des steps.
Un step n'est rien d'autre qu'une tâche unitaire nécessaire pour effectuer le job. Ça peut être du code shell ou du python, mais également des actions ; c'est là la force de Github Actions.
Les actions sont des applications pour Github Actions exécutant des tâches complexes, mais répétitives. Là où l'on devait avant créer du code personnalisé pour effectuer des étapes répétitives (comme Jenkins) ou importer des blocks d'exécutions non paramétrables (include + extends sous Gitlab CI/CD), les actions permettent cela nativement et facilement.
En effet, l'un des plus gros avantages des actions est qu'elles peuvent être gérées directement par la communauté. Grâce à cela, plus besoin de maintenir la compatibilité de nos scripts... à condition que la communauté en question y fasse attention également. Par exemple, dans notre cas d'exemple, nous allons utiliser des actions directement issues des repos de Hashicorp ; nous sommes donc sûrs que ces actions seront mises à jour et suivront l'évolution de Terraform.
Cependant, les actions viennent également avec leurs lots de contraintes. La première est bien évidemment l'abstraction ; en utilisant des composants externes, on ne sait pas exactement ce qui est exécuté, ni comment. Si quelque chose ne fonctionne pas, il peut également être compliqué d'investiguer et d'en connaitre la raison.
La seconde, qui résulte de la première, est un risque pour la sécurité. Du fait qu'il y ait de l'abstraction et que les actions soient créées et gérées par des personnes externes ajoute un risque de sécurité supplémentaire, comme la fuite de code source ou l'injection de faille lors de la compilation. Ce risque est notamment accru si on les utilise à tort et à travers.
Bien heureusement, il existe des moyens de mitiger au mieux ce problème en suivant quelques bonnes pratiques.
Comme pour les jobs il y a quelques champs requis pour exécuter une action au sein d'un step :
name). Comme pour les jobs, c'est optionnel, mais ça facilite grandement la lecture des logs dans Github. C'est pourquoi je vous le conseille vivement dans la majorité des cas.uses). Par exemple, pour cloner le repo sur la bonne branche, on va utiliser généralement actions/checkout@v2.with). Cela n'est pas toujours requis ; par exemple actions/checkout@v2 va utiliser le contexte fourni par Github pour déterminer quel repo cloner et quelle branche utiliser.
Nous reparlerons du contexte plus tard.En voici quelques exemples :
- name: Checkout repository code uses: actions/checkout@v2 - name: Setup Terraform 1.1.2 uses: hashicorp/setup-terraform@3d8debd658c92063839bc97da5c2427100420dec # nous pouvons également utiliser le SHA d'un commit en particulier (ici, celui de la v1.3.2) with: terraform_version: 1.1.2
Dans certains cas, nous n'avons pas vraiment besoin d'utiliser des actions pour arriver à nos fins. Dans ces cas-là, nous pouvons directement exécuter du code shell ou python. Pour cela, il suffit d'utiliser run dans la définition du step.
En voici quelques exemples :
- name: Debug environment run: env - name: Rewrites all Terraform configuration files to a canonical format run: terraform fmt .
Les contextes sont un moyen d'accéder à des informations à propos du workflow en cours, de l'environnement d'exécution ou des précédents jobs et steps exécutés.
Attention, comme précisé dans la documentation, les contextes peuvent être manipulés et doivent être traités comme sources pouvant contenir des informations malicieuses
L'accès à ces informations se fait au travers de la syntaxe ${{ context }}. Je ne vais pas en parler directement dans cet article, car la documentation en parlera probablement mieux que moi et qu'il y a beaucoup de chose à dire dessus. Voici les deux pages de documentation que je vous conseille si vous voulez approfondir ce sujet :
On a vu précédemment les deux façons d'écrire des step ; il est donc temps de revenir sur notre workflow. Mais juste avant, tout comme les workflows et les jobs, les steps ont quelques champs optionnels que voici :
if)env).
Je ne l'ai pas précisé avant, mais il est également possible de faire ça au niveau d'un job complet ou même du workflow.step (id). Cela permet de pouvoir utiliser les retours d'une action depuis le contexte, ou d'avoir une condition sur l'état d'exécution d'un step précédent.Il y en quelques autres qu'on ne verra pas dans cet article. Mais comme toujours, la documentation officielle est très bien fournie.
Commençons par notre premier job : lint
Comme définit précédemment, notre premier job est chargé de vérifier la syntaxe et le formatage des fichiers Terraform. Pour cela, nous allons utiliser deux commandes incluses dans le CLI de Terraform : terraform fmt et terraform validate.
Voici donc les différentes étapes :
uses: actions/checkout@ec3a7ce113134d7a93b817d10a8272cb61118579terraform pour pouvoir l'utilser dans les étapes suivantes
uses: hashicorp/setup-terraform@3d8debd658c92063839bc97da5c2427100420decrun: terraform init -no-color -backend=false
-backend=false ici, car on ne fait le init ici que pour télécharger toutes les dépendances requises pour le terraform validaterun: terraform validate -no-colorrun: terraform fmt -check -recursive -diff -no-color .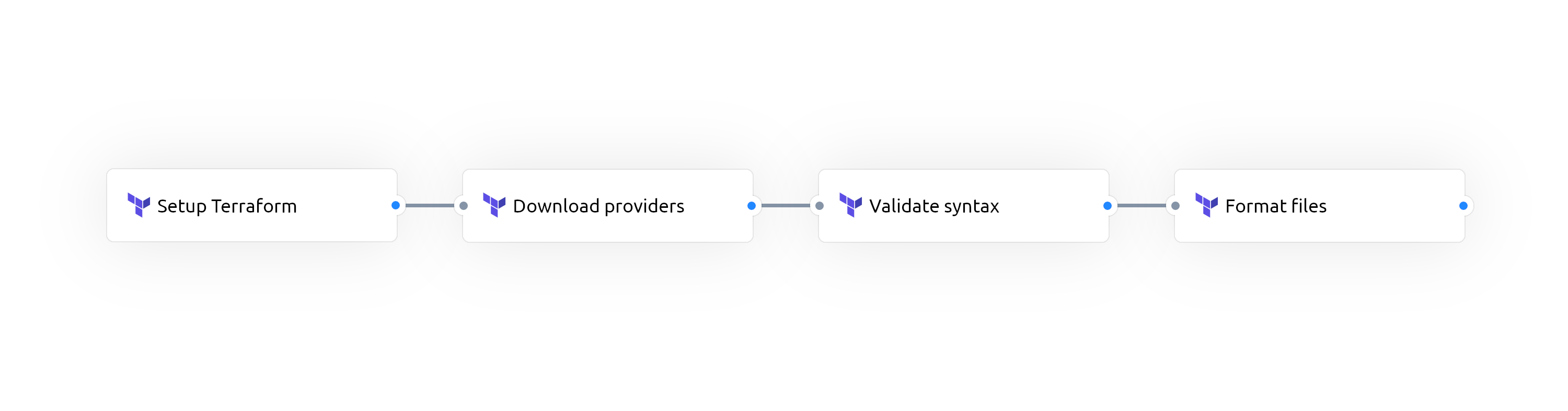
Voici donc la définition YAML de notre premier job :
lint: name: Format & validate Terraform files runs-on: ubuntu-latest steps: - name: Checkout repository code uses: actions/checkout@ec3a7ce113134d7a93b817d10a8272cb61118579 - name: Setup Terraform 1.1.2 uses: hashicorp/setup-terraform@3d8debd658c92063839bc97da5c2427100420dec - name: Initialize Terraform working directory run: terraform init -no-color -backend=false - name: Validate the configuration files run: terraform validate -no-color - name: Check if all Terraform configuration files are in a canonical format run: terraform fmt -check -recursive -diff -no-color
Passons maintenant au second job : plan
La seule différence avec le premier est l'utilisation de terraform plan.
Voici donc les différentes étapes pour le second :
uses: actions/checkout@ec3a7ce113134d7a93b817d10a8272cb61118579uses: hashicorp/setup-terraform@3d8debd658c92063839bc97da5c2427100420decrun: terraform init -no-colorrun: terraform plan -input=false -no-color -compact-warnings
Voici donc la définition YAML de notre second job
plan: name: Generates a speculative execution plan runs-on: ubuntu-latest needs: [lint] # on exécute ce job uniquement si le précédent a réussi concurrency: tf-plan # on fait en sorte d'éviter toute concurrence lors du Terraform plan steps: - name: Checkout repository code uses: actions/checkout@ec3a7ce113134d7a93b817d10a8272cb61118579 - name: Setup Terraform 1.1.2 uses: hashicorp/setup-terraform@3d8debd658c92063839bc97da5c2427100420dec - name: Initialize Terraform working directory env: AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }} AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }} run: terraform init -no-color - name: Generate a speculative execution plan # S'il y a besoin d'utiliser des variables, c'est faisable via les variables d'environnement # env: # TF_VARS_...: ... run: terraform plan -input=false -no-color -compact-warnings
${{ secrets.AWS_ACCESS_KEY_ID }}permet d'utiliser des variables donc le contenu peut être sensible. Ce valeurs sont configurables directement dans Github et leur valeur ne seront jamais affichées dans les logs de la CI.
Maintenant que les jobs et steps ont été défini, il est temps d'assembler les différentes parties pour obtenir notre workflow final :
name: Terraform CI on: pull_request: jobs: lint: name: Format & validate Terraform files runs-on: ubuntu-latest steps: - name: Checkout repository code uses: actions/checkout@ec3a7ce113134d7a93b817d10a8272cb61118579 - name: Setup Terraform 1.1.2 uses: hashicorp/setup-terraform@3d8debd658c92063839bc97da5c2427100420dec - name: Initialize Terraform working directory run: terraform init -no-color -backend=false - name: Validate the configuration files run: terraform validate -no-color - name: Check if all Terraform configuration files are in a canonical format run: terraform fmt -check -recursive -diff -no-color plan: name: Generates a speculative execution plan runs-on: ubuntu-latest needs: [lint] # on exécute ce job uniquement si le précédent a réussi concurrency: tf-plan # on fait en sorte d'éviter toute concurrence lors du Terraform plan steps: - name: Checkout repository code uses: actions/checkout@ec3a7ce113134d7a93b817d10a8272cb61118579 - name: Setup Terraform 1.1.2 uses: hashicorp/setup-terraform@3d8debd658c92063839bc97da5c2427100420dec - name: Initialize Terraform working directory env: AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }} AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }} run: terraform init -no-color - name: Generate a speculative execution plan # S'il y a besoin d'utiliser des variables, c'est faisable via les variables d'environnement # env: # TF_VARS_...: ... run: terraform plan -input=false -no-color -compact-warnings
Avant de conclure cet article, j'aimerais partager avec vous ces quelques bonnes pratiques qui vous permettront de réduire au mieux les inconvénients des Github Actions
uses: actions/checkout@v2, faites plutôt uses: actions/checkout@ec3a7ce113134d7a93b817d10a8272cb61118579.
Cela permet d'être toujours sûr de savoir quelle version du code on utilise et ainsi de faciliter l'audit dessus.${{ secret.NOM_DU_SECRET }}. La définition des secrets se fait dans la configuration du repository ou dans celle de l'organisation (pour des secrets partagés entre plusieurs repos d'une organisation)Nous avons pu construire notre premier workflow tout au long de cet article, en voyant les différents concepts que sont les workflows, les jobs ainsi que les steps. Nous avons fait un tour rapide de la syntaxe de chacun et parlé des quelques bonnes pratiques. Mais malgré cela, nous n'avons qu'effleuré la surface des possibilités (et de la complexité) des Github Actions et il reste tant de choses à voir, comme son utilisation pour la gestion des tickets par exemple (attribuer des étiquettes automatiquement, fermer des issues/PRs trop anciennes...).
Le workflow créé dans cet article est pratique, mais quelque peu austère ; s'il y a un problème, le workflow échoue et nous force à aller chercher dans les logs du workflow pour savoir pourquoi.
Pourquoi ne pas commenter la PR avec la source du problème ? Et pourquoi ne pas rajouter le plan au passage ? C'est ce que je vais vous montrer en utilisant l'action marocchino/sticky-pull-request-comment:
name: Terraform CI on: pull_request: jobs: lint: name: Format & validate Terraform files runs-on: ubuntu-latest steps: - name: Checkout repository code uses: actions/checkout@ec3a7ce113134d7a93b817d10a8272cb61118579 - name: Setup Terraform 1.1.2 uses: hashicorp/setup-terraform@3d8debd658c92063839bc97da5c2427100420dec - name: Initialize Terraform working directory id: init run: terraform init -no-color -backend=false - name: Annotate the PR if the previous step fail if: failure() && steps.init.outcome == 'failure' # on commente uniquement si le step avec l'id `init` échoue uses: marocchino/sticky-pull-request-comment@39c5b5dc7717447d0cba270cd115037d32d28443 with: recreate: true message: | # Terraform CI - [ ] :hammer_and_wrench: Validate the configuration files ### 🚫 Failure reason ```terraform ${{ steps.init.outputs.stdout }} ``` <br/> > _Report based on commit ${{ github.sha }} (authored by **@${{ github.actor }}**). See [`actions#${{ github.run_id }}`](https://github.com/${{ github.repository }}/actions/runs/${{ github.run_id }}) for more details._ - name: Validate the configuration files id: validate run: terraform validate -no-color - name: Annotate the PR if the previous step fail if: failure() && steps.validate.outcome == 'failure' # on commente uniquement si le step avec l'id `validate` échoue uses: marocchino/sticky-pull-request-comment@39c5b5dc7717447d0cba270cd115037d32d28443 with: recreate: true message: | # Terraform CI - [ ] :hammer_and_wrench: Validate the configuration files ### 🚫 Failure reason ```terraform ${{ steps.validate.outputs.stdout }} ``` <br/> > _Report based on commit ${{ github.sha }} (authored by **@${{ github.actor }}**). See [`actions#${{ github.run_id }}`](https://github.com/${{ github.repository }}/actions/runs/${{ github.run_id }}) for more details._ - name: Check if all Terraform configuration files are in a canonical format id: fmt run: terraform fmt -check -recursive -diff -no-color - name: Annotate the PR if the previous step fail if: failure() && steps.fmt.outcome == 'failure' # on commente uniquement si le step avec l'id `fmt` échoue uses: marocchino/sticky-pull-request-comment@39c5b5dc7717447d0cba270cd115037d32d28443 with: recreate: true message: | # Terraform CI - [x] :hammer_and_wrench: Validate the configuration files - [ ] :paintbrush: Check if all Terraform configuration files are in a canonical format ### 🚫 Failure reason ```terraform ${{ steps.fmt.outputs.stdout }} ``` <br/> > _Report based on commit ${{ github.sha }} (authored by **@${{ github.actor }}**). See [`actions#${{ github.run_id }}`](https://github.com/${{ github.repository }}/actions/runs/${{ github.run_id }}) for more details._ plan: name: Generates a speculative execution plan runs-on: ubuntu-latest needs: [lint] # on exécute ce job uniquement si le précédent a réussi concurrency: tf-plan # on fait en sorte d'éviter toute concurrence lors du Terraform plan steps: - name: Checkout repository code uses: actions/checkout@ec3a7ce113134d7a93b817d10a8272cb61118579 - name: Setup Terraform 1.1.2 uses: hashicorp/setup-terraform@3d8debd658c92063839bc97da5c2427100420dec - name: Initialize Terraform working directory env: AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }} AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }} id: init run: terraform init -no-color - name: Annotate the PR if the previous step fail if: failure() && steps.init.outcome == 'failure' # on commente uniquement si le step avec l'id `init` échoue uses: marocchino/sticky-pull-request-comment@39c5b5dc7717447d0cba270cd115037d32d28443 with: recreate: true message: | # Terraform CI - [x] :hammer_and_wrench: Validate the configuration files - [x] :paintbrush: Check if all Terraform configuration files are in a canonical format - [ ] :scroll: Generate a speculative execution plan ### 🚫 Failure reason ```terraform ${{ steps.init.outputs.stdout }} ``` <br/> > _Report based on commit ${{ github.sha }} (authored by **@${{ github.actor }}**). See [`actions#${{ github.run_id }}`](https://github.com/${{ github.repository }}/actions/runs/${{ github.run_id }}) for more details._ - name: Generate a speculative execution plan id: plan run: terraform plan -input=false -no-color -compact-warnings - name: Annotate the PR if the previous step fail if: failure() && steps.plan.outcome == 'failure' # on commente uniquement si le step avec l'id `plan` échoue uses: marocchino/sticky-pull-request-comment@39c5b5dc7717447d0cba270cd115037d32d28443 with: recreate: true message: | # Terraform CI - [x] :hammer_and_wrench: Validate the configuration files - [x] :paintbrush: Check if all Terraform configuration files are in a canonical format - [ ] :scroll: Generate a speculative execution plan ### 🚫 Failure reason ```terraform ${{ steps.plan.outputs.stdout }} ``` <br/> > _Report based on commit ${{ github.sha }} (authored by **@${{ github.actor }}**). See [`actions#${{ github.run_id }}`](https://github.com/${{ github.repository }}/actions/runs/${{ github.run_id }}) for more details._ - name: Annotate the PR if the plan step succeed if: success() # on commente uniquement tout a réussi uses: marocchino/sticky-pull-request-comment@39c5b5dc7717447d0cba270cd115037d32d28443 with: recreate: true message: | # Terraform CI - [x] :hammer_and_wrench: Validate the configuration files - [x] :paintbrush: Check if all Terraform configuration files are in a canonical format - [x] :scroll: Generate a speculative execution plan ### Terraform Plan output ```terraform ${{ steps.plan.outputs.stdout }} ``` <br/> > _Report based on commit ${{ github.sha }} (authored by **@${{ github.actor }}**). See [`actions#${{ github.run_id }}`](https://github.com/${{ github.repository }}/actions/runs/${{ github.run_id }}) for more details._
C'est très verbeux, mais cela facilite grandement la review de PRs car on sait exactement pourquoi le workflow échoue ou quelles vont être les modifications sur l'infrastructure.
Auteur(s)
Vous souhaitez en savoir plus sur le sujet ?
Organisons un échange !
Notre équipe d'experts répond à toutes vos questions.
Nous contacterDécouvrez nos autres contenus dans le même thème
Sécuriser votre serveur avec des certificat SSL pour tous vos sous-domaines grâce au DNS challenge

Ce guide présente Apache Iceberg, un format de table moderne pour les données volumineuses, la gestion des versions et des performances optimisées.

Plongez dans le monde des AST et découvrez comment cette structure de données fondamentale révolutionne le développement moderne.