
Créer un Delta Lake avec Apache Spark
Il existe différents formats de fichier pour stocker la donnée : parquet, avro, csv. Connaissez-vous le format Delta Lake ? Découvrons ensemble les fonctionnalités de ce format.

Dans cet article, je vous propose de vous mettre dans la peau d'un Data Analyst. Sous forme de cas pratique, nous allons répondre à des questions en nous aidant d'outils d'analyse de données.
Avant de vous expliquer comment j'ai procédé, je vous donne un peu de contexte.
Lors de l'acquisition d'un bien immobilier, il faut souscrire à un fournisseur d'électricité. Une fois le fournisseur d'électricité sélectionné, il existe deux types d'offres généralement : tarif de base, et tarif heures creuses / heures pleines (généralement abbrégé HC-HP). En plus de ces offres, il existe des déclinaisons pour les véhicules électriques, ou avec de l'électricité produite à partir de sources renouvelables.
La tarification heures creuses propose un prix assez bas du kilowatt-heure. En contre-partie, l'abonnement et le prix du kilowatt-heure en heures pleines est plus cher. Les périodes d'heures creuses/pleines sont déterminées par le gestionnaire du réseau Enedis. Ces périodes correspondent à des moments de faible charge du réseau.
Avec tous ces tarifs, il n'est pas évident de s'y retrouver. Quand le bien immobilier a son chauffage au gaz, il est en général conseillé de prendre le tarif de base. Si le chauffage est électrique et qu'il y un chauffe-eau électrique à accumulation, il est alors conseillé de prendre le tarif HC-HP. Cela permet de chauffer l'eau durant les périodes creuses pour économiser de l'argent.
En choisissant un tarif HC-HP, il est possible de faire baisser ses coûts en consommation électrique. Cependant, il faut veiller à consommer le plus possible durant la période creuse. Cela signifie par exemple, lancer le lave-linge et le lave-vaisselle à ces moments.
La question que l'on peut se poser est donc : est-ce que la tarification HC-HP est vraiment avantageuse ?
Voyons les outils que nous allons utiliser.
Dans ce cas pratique, en tant qu'analyste de données (ou en anglais "Data Analyst"), je vais faire l'analyse du problème et y répondre. Je vais m'appuyer sur des outils tel que Pandas pour la manipulation des données et plotly pour la création de visualisation de données. Tout cela en Python et dans un notebook Jupyter.
J'ai sélectionné ces outils car ce sont les plus utilisés dans ce domaine. Il est tout à fait possible d'utiliser une feuille de calcul tel que LibreOffice Calc ou Microsoft Excel, mais le but de ce cas pratique est d'utiliser des outils spéciques à la manipulation des données en Python.
Maintenant que vous avez le contexte, on met les main dedans et on rentre dans le sujet. Je vais tout d'abord commencer par trouver les sources de données.
Pour effectuer mon analyse, j'ai besoin de données. Dans un premier temps, il me faut les données sur les différents tarifs et ensuite il me faut les données sur ma consommation. Allons tout d'abord récupérer les données sur les tarifs de l'électricités.
Pour faire simple, je vais sélectionner EDF comme fournisseur d'électricité. Il est tout à fait possible d'en ajouter davantage pour comparer.
Généralement, l'information sur la tarification n'est pas accessible du premier coup sur le site internet. Il faut fouiller un peu. Quand la page est trouvée, la tarification est dans un document pdf.
J'ai sélectionné 4 tarifs :
Note : Par souci de rigueur, je ne peux pas sélectionner le tarif bleu HC-HP car je n'ai pas de données sur ma consommation en HC-HP durant le weekend.
J'ai copié chaque valeur dans un tableau et sauvegardé dans un fichier OpenDocument (.ods). Le choix du format n'a pas d'importance. Cependant, pour faciliter leurs ingestions il faut garder une uniformité dans le format et la structure des données.
| kva | abonnement | heure pleine | heure creuse | heure weekend |
|---|---|---|---|---|
| 6 | 11,8 | 22,35 | 15,21 | 15,21 |
| 9 | 15,3 | 22,35 | 15,21 | 15,21 |
| 12 | 18,48 | 22,35 | 15,21 | 15,21 |
| 15 | 21,58 | 22,35 | 15,21 | 15,21 |
| 18 | 24,52 | 22,35 | 15,21 | 15,21 |
La première colonne est la puissance maximale qu'il est possible de soutirer. Cette puissance est mesurée en kilo-voltampère (kVA).Au-delà, le contacteur du compteur Linky s'ouvre pour couper l'alimentation de l'abonné.
En seconde colonne, c'est le prix de l'abonnement mensuel en euro. Enfin, les autres colonnes sont les tarifs du kWh en centimes d'euros.
Une fois que j'ai les données sur la tarification de l'électricité, je peux aller chercher les données sur la consommation.
Avec le déploiement des compteurs Linky, la consommation (et la production) d'électricité est remontée quotidiennement chez le gestionnaire de réseau Enedis. Les fournisseurs d'électricité demandent à Enedis la consommation électrique de chaque Point De Livraison (PDL) pour ainsi facturer au client final.
Enedis permet au client de consulter ses données quotidiennes. Je vous renvoie vers un article Enedis pour récupérer les données de consommation https://www.enedis.fr/jaccede-mes-donnees-de-consommation-et-de-production-delectricite. Pour notre étude, j'ai pris les données sur 1 mois.
Nous avons les données sur les tarifs de l'électricité et les données sur la consommation. Cependant, le format des données sur la consommation est difficile à exploiter... Nous devons donc la nettoyer !
Les données de consommation récupérées auprès d'Enedis sont assez chaotiques. Il n'est pas possible de fournir ce fichier à Pandas car il ne saura pas l'organiser.
Ci-dessous un extrait du fichier fournis par Enedis.
Identifiant PRM;Type de donnees;Date de debut;Date de fin;Grandeur physique;Grandeur metier;Etape metier;Unite 00000000000000;Index;12/04/2021;18/04/2021;Energie active;Consommation;Comptage Brut;Wh Horodate;Type de releve;EAS F1;EAS F2;EAS F3;EAS F4;EAS F5;EAS F6;EAS F7;EAS F8;EAS F9;EAS F10;EAS D1;EAS D2;EAS D3;EAS D4;EAS T 2021-04-01T01:00:00+02:00;Arrêté quotidien;11538434;12944147;3668104;;;;;;;;19416294;2543931;2686684;3503776;28150685 Periode;Identifiant calendrier fournisseur;Libelle calendrier fournisseur;Identifiant classe temporelle 1;Libelle classe temporelle 1;Cadran classe temporelle 1; Du 2021-04-12T00:00:00+01:00 au;AA000000;Option Heures Creuses + Week-End;HC;Heures Creuses;EAS F1;HP;Heures Pleines;
Les données de consommation ont une structure spécifique. Les deux premières lignes sont des en-tête qui décrivent la nature des données. Un élément doit attirer notre attention : la consommation est en watt-heure et c'est du cumulatif (comme un compteur kilométrique d'une voiture).
La troisième ligne ce sont les noms de colonnes. Ces noms sont des index de colonnes. Les labels plus détails sont dans les 2 dernières lignes du tableau.
Ce sont des metadonnées qui donnent des informations supplémentaires à la donnée en elle-même, mais elles ne sont pas utiles pour exploiter les informations.
Par exemple, pour la colonne EAS F1 j'ai la valeur 11538434. En regardant les deux dernière lignes du tableau, je vois :
Identifiant classe temporelle 1;Libelle classe temporelle 1;Cadran classe temporelle 1 EAS F1 ;HP ;Heures Pleines
Donc la colonne EAS F1 correspond à la consommation en Heures Pleines.
Au final, ce sont les colonnes EAS F1, EAS F2, EAS F3 qui correspondent à la consommation en heures pleines, heures creuses et weekend.
Dans un premier temps je supprime les deux premières lignes d'en-tête et les deux dernières lignes, je veux conserver uniquement la données concernant la consommation et ne veux pas de métadonnées dans le fichier final.
BASE_PATH = "datalake/" RAW_DATA_FILENAME = "sample.csv" RAW_DATA_CLEANED_FILENAME = "enedis_conso_clean.csv" CLEANED_DATA_FILENAME = "enedis-data-ready-to-work.parquet" with open(f"{BASE_PATH}{RAW_DATA_FILENAME}", "r+") as fp: lines = fp.readlines() with open(f"{BASE_PATH}{RAW_DATA_CLEANED_FILENAME}", "w+") as fpclean: fpclean.writelines(lines[2: len(lines) - 2])
Un nouveau fichier nettoyé est généré : enedis_conso_clean.csv. Ensuite, je charge ce nouveau fichier avec Pandas pour effectuer quelques calculs de base, comme le différentiel par jour et la consommation totale de la journée.
Avec Pandas, le travail sur les données s'effectue en colonnes et non en lignes. Ce fonctionnement est un peu déroutant lorsque l'on utilise couramment des bases de données tel que MySQL ou PostgreSQL.
import pandas as pd df = pd.read_csv(f"{BASE_PATH}{RAW_DATA_CLEANED_FILENAME}", sep=";") # Calcul de la consommation totale de la journée df["Total Consommation"] = df["EAS F2"] + df["EAS F1"] + df["EAS F3"] # Renommage des colonnes df_work = df[["Horodate", "EAS F1", "EAS F2", "EAS F3", "Total Consommation"]].copy() df_work.columns = [ "Horodate", "Quantité Heure Creuse en wh", "Quantité Heure Pleine en wh", "Quantité Weekend en wh", "Total Consommation", ] # Calcul de la différence par rapport à la journée précédente pour chaque colonne. df_work["Différence journalier Total Consommation"] = df_work["Total Consommation"].diff() df_work["Différence journalier Heure Creuse"] = df_work["Quantité Heure Creuse en wh"].diff() df_work["Différence journalier Heure Pleine"] = df_work["Quantité Heure Pleine en wh"].diff() df_work["Différence journalier Weekend"] = df_work["Quantité Weekend en wh"].diff() # Sauvegarde du traitement dans un fichier Apache Parquet df_work.to_parquet(f"{BASE_PATH}{CLEANED_DATA_FILENAME}")
Cela nous donne ce tableau.
| Horodate | Quantité Heure Creuse en wh | Quantité Heure Pleine en wh | Quantité Weekend en wh | Total Consommation | Différence journalier Total Consommation | Différence journalier Heure Creuse | Différence journalier Heure Pleine | Différence journalier Weekend |
|---|---|---|---|---|---|---|---|---|
| 2021-04-01T01:00:00+02:00 | 11538434 | 12944147 | 3668104 | 28150685 | NaN | NaN | NaN | NaN |
| 2021-04-02T01:00:00+02:00 | 11543332 | 12948970 | 3668104 | 28160406 | 9721.0 | 4898.0 | 4823.0 | 0.0 |
| 2021-04-03T01:00:00+02:00 | 11550420 | 12954810 | 3668104 | 28173334 | 12928.0 | 7088.0 | 5840.0 | 0.0 |
| 2021-04-04T01:00:00+02:00 | 11550420 | 12954810 | 3683924 | 28189154 | 15820.0 | 0.0 | 0.0 | 15820.0 |
| 2021-04-05T01:00:00+02:00 | 11550420 | 12954810 | 3700863 | 28206093 | 16939.0 | 0.0 | 0.0 | 16939.0 |
| 2021-04-06T01:00:00+02:00 | 11550420 | 12954810 | 3715235 | 28220465 | 14372.0 | 0.0 | 0.0 | 14372.0 |
Il est à noter que les colonnes qui contiennent le calcul de la différence journalier sur la première ligne contiennent la valeur NaN. Couramment, la valeur NaN signifie "Not A Number" surtout lorsque le typage de la colonne est un nombre floattant (float64). Mais avec Pandas, cela signifie qu'il manque une valeur. Ici c'est tout à fait normal, car il n'y a rien à comparer avant, cela ne gêne pas pour la suite des calculs.
Pour finir, je choisis de stocker le résultat dans un format Apache Parquet car il permet de stocker le schéma des données. Ce format est adapté aux données de type colonne et permet un stockage efficace (compression). Nos données sont prêtes pour l'analyse.
Pour rappel, le but de notre analyse est de répondre à la question suivante : est-ce que la tarification HC-HP est vraiment avantageuse ?
Pour cela, je vais procéder en deux étapes :
Effectuons le calcul pour obtenir la répartition de la consommation.
Dans un premier temps, je vais regarder la répartition de la consommation entre les différentes périodes. Quelle est la part d'heures creuse, d'heures pleines et weekend ?
import pandas as pd df = pd.read_parquet("datalake/enedis-data-ready-to-work.parquet") repartition_consommation = pd.DataFrame( { "Consommation par periode en kWh": [ df["Différence journalier Heure Pleine"].sum() / 1000, df["Différence journalier Heure Creuse"].sum() / 1000, df["Différence journalier Weekend"].sum() / 1000, ], "Périodes": ["Heure Pleine", "Heure Creuse", "Weekend"], } ) repartition_consommation
Cela me donne le tableau suivant.
| Consommation par periode en kWh | Périodes |
|---|---|
| 132.935 | Heure Pleine |
| 158.837 | Heure Creuse |
| 136.113 | Weekend |
La lecture du tableau ne permet pas de se rendre compte de cette répartition. Ajoutons un graphique en camembert.
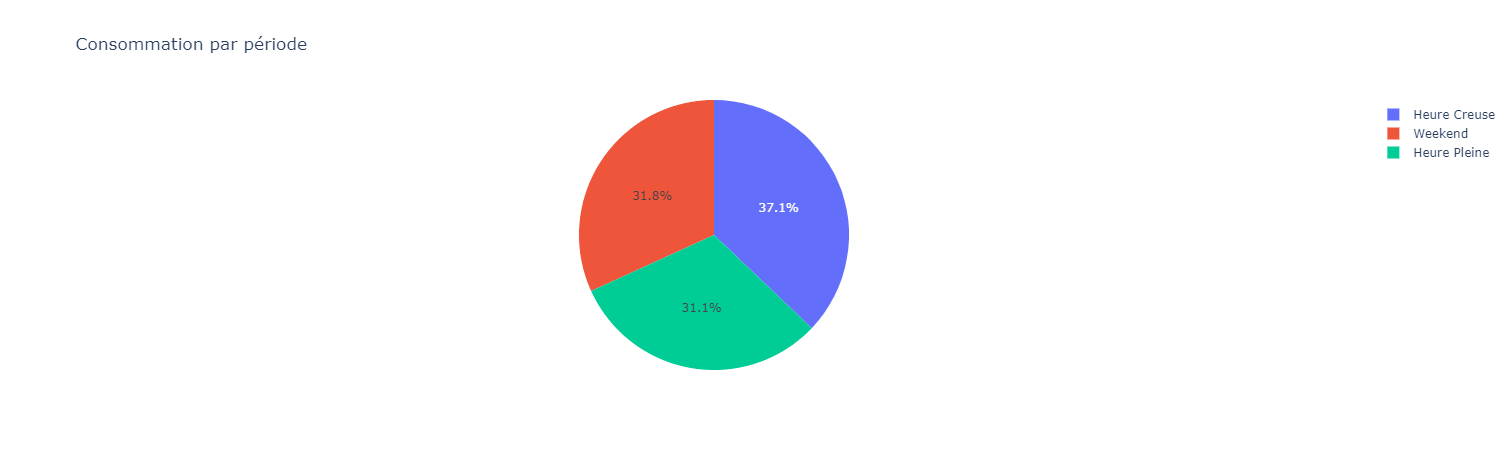
C'est mieux :)
Cela me permet de voir que ~69% de ma consommation électrique est dans la tarification creuse (le weekend c'est la tarification heure creuse qui est utilisée).
Maintenant, appliquons le prix de l'électricité à la consommation électrique. Cela va nous donner le coût total.
Je vais faire l'analyse avec les tarifs de l'électricité que j'ai récupérés auprès de mon fournisseur. Dans la grille tarifaire, chaque ligne correspond à une puissance électrique apparente maximale mesurée en kilovoltampère (kVA). Je vous renvoie à Wikipédia pour plus d'explications https://fr.wikipedia.org/wiki/Voltamp%C3%A8re.
Pour notre cas, ça sera 9 kVA.
Ci-dessous j'expose le code du calcul pour le tarif vert weekend hc-hp
# Je charge le fichier de tarification et je sélectionne la ligne avec 9 kVA df_tarif_vert_weekend_hp_hc = pd.read_excel("datalake/tarif-vert-weekend-hc-hp.ods") selected_df_tarif_vert_weekend_hp_hc = df_tarif_vert_weekend_hp_hc.loc[df_tarif_vert_weekend_hp_hc["kva"] == 9] selected_df_tarif_vert_weekend_hp_hc.reset_index(drop=True, inplace=True) # Remise à zéro de l'index du tableau # Je crée un nouveau tableau avec le calcul de consommation multiplié par le tarif du kWh. Attention aux unités. cout_tarif_vert_weekend_hp_hc = pd.DataFrame(columns=["cout heure creuse", "cout heure pleine", "cout weekend"]) cout_tarif_vert_weekend_hp_hc["cout heure creuse"] = (df["Différence journalier Heure Creuse"] / 1000) * (selected_df_tarif_vert_weekend_hp_hc["heure creuse"].values[0] / 100) cout_tarif_vert_weekend_hp_hc["cout heure pleine"] = (df["Différence journalier Heure Pleine"] / 1000) * (selected_df_tarif_vert_weekend_hp_hc["heure pleine"].values[0] / 100) cout_tarif_vert_weekend_hp_hc["cout weekend"] = (df["Différence journalier Weekend"] / 1000) * (selected_df_tarif_vert_weekend_hp_hc["heure weekend"].values[0] / 100) cout_tarif_vert_weekend_hp_hc["total"] = cout_tarif_vert_weekend_hp_hc["cout weekend"] + cout_tarif_vert_weekend_hp_hc["cout heure pleine"] + cout_tarif_vert_weekend_hp_hc["cout heure creuse"] # j'ajoute le coût de l'abonnement au total calculated_cout_tarif_vert_weekend_hp_hc = cout_tarif_vert_weekend_hp_hc["total"].sum() + selected_df_tarif_vert_weekend_hp_hc["abonnement"].values[0]
Je répète cette opération pour tous les tarifs que j'ai sélectionnés.
Cela me permet de tracer ce graphique avec Plotly.
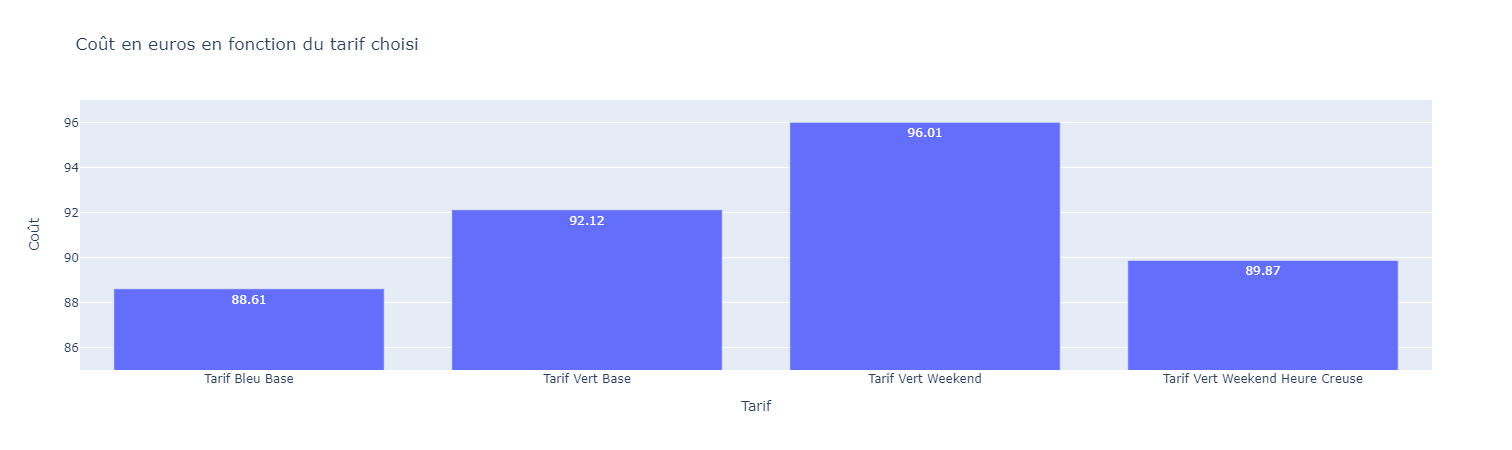
Il nous donne les informations nécessaires pour répondre à notre question initiale, à nous de l'interpréter.
En comparant le tarif vert de base et tarif vert weekend HC-HP, il y a bien une différence de 2,25 euros (soit une différence de 2,44%). Cela représente 27 euros par an. Donc pour répondre à la question initiale : oui, la tarification HC-HP est avantageuse par rapport à une tarification de base.
Cependant, cette interprétation est à nuancer.
L'analyse est effectuée pour une répartition de la consommation donnée. Chaque foyer à une consommation différente, donc la répartition de la consommation est différente.
Si je compare la tarification vert weekend HC-HP et le tarif bleu de base, la réponse à la question est inversée. En observant la grille tarifaire, le tarif vert est plus cher que le bleu. On peut alors se demander : "pourquoi ?" Je laisse cette question ouverte car elle dépasse notre cas étudié.
Pour conclure, ce cas a permis de mettre en pratique des outils utilisés dans le domaine de la Data. Notebook IPython et la bibliothèque Pandas sont des incourtournables qu'il est nécessaire de maitriser.
Sur cette base d'analyse, il est possible d'approfondir le sujet en appliquant une modèle prédictif à l'aide du machine learning par exemple. Tout est possible, la donnée est disponible, il ne reste plus qu'à l'exploiter !
Auteur(s)
Thierry T.
Super Data Boy
Vous souhaitez en savoir plus sur le sujet ?
Organisons un échange !
Notre équipe d'experts répond à toutes vos questions.
Nous contacterDécouvrez nos autres contenus dans le même thème
Il existe différents formats de fichier pour stocker la donnée : parquet, avro, csv. Connaissez-vous le format Delta Lake ? Découvrons ensemble les fonctionnalités de ce format.

Il arrive qu'une fonction ou action ne puisse pas être réalisée à un instant donné. Cela peut être dû à plusieurs facteurs qui ne sont pas maîtrisés. Il est alors possible d'effectuer une nouvelle tentative plus tard. Dans cet article, voyons comment le faire.

Le formatage du code est une source de querelle entre les membres d'une équipe. Résolvons-le une bonne fois pour toute avec le formateur de code Black.