
Dependency injection in Symfony
You work with Symfony, but the concept of dependency injection is a little blurry for you? Find out how to take advantage of the component reading this article.

![]()
RabbitMQ is a message broker, allowing to process things asynchronously. There's already an article written about it, if you're not familiar with RabbitMQ.
What I'd like to talk to you about is the lifecycle of a message, with error handling. Everything in a few lines of code.
Therefore, we're going to configure a RabbitMQ virtual host, publish a message, consume it and retry publication if any error occurs.
The technical solution is based on two libraries:
Swarrot is compatible with the amqp extension of PHP, as well as the php-amqplib library. The PHP extension has a certain advantage on performance (written in C) over the library, based on benchmarks. To install the extension, click here. The main adversary to Swarrot, RabbitMqBundle, is not compatible with the PHP extension, and is not as simple in both configuration and usage.
Our first step will be to create our RabbitMQ configuration: our exchange and our queue.
The RabbitMQ Admin Toolkit library, developed by odolbeau, allows us to configure our vhost very easily. Here is a basic configuration declaring an exchange and a queue, allowing us to send our mascot Wilson and his fellow friends to space:
# default_vhost.yml '/': parameters: with_dl: false # If true, all queues will have a dl and the corresponding mapping with the exchange "dl" with_unroutable: false # If true, all exchange will be declared with an unroutable config exchanges: default: type: direct durable: true queues: send_astronaut_to_space: durable: true bindings: - exchange: default routing_key: send_astronaut_to_space
Here, we ask the creation of an exchange named "default", and a queue named "send_astronaut_to_space", bound to our exchange via a homonym routing key. A binding represents a relation between a queue and an exchange.
Let's launch the command to create our vhost:
vendor/bin/rabbit vhost:mapping:create default_vhost.yml --host=127.0.0.1 Password? With DL: false With Unroutable: false Create exchange default Create queue send_astronaut_to_space Create binding between exchange default and queue send_astronaut_to_space (with routing_key: send_astronaut_to_space)
If you connect to the RabbitMQ management interface (ex: http://127.0.0.1:15672/), many things will appear:
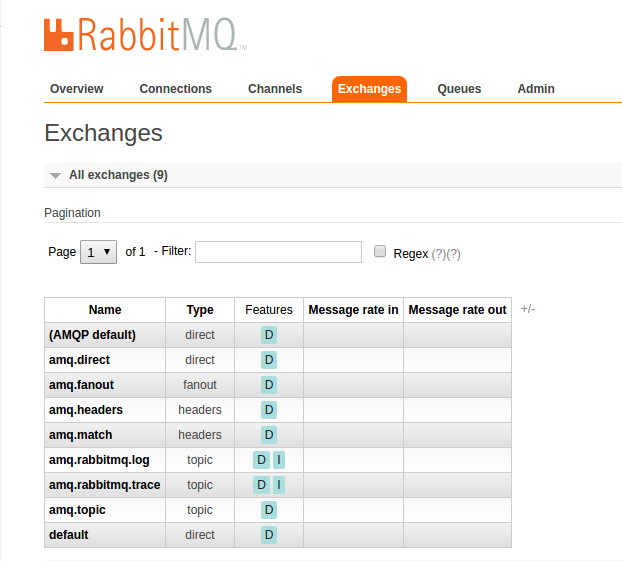
Click on the Exchanges tab: an exchange named default has been created, with a binding to our queue as indicated in our terminal.
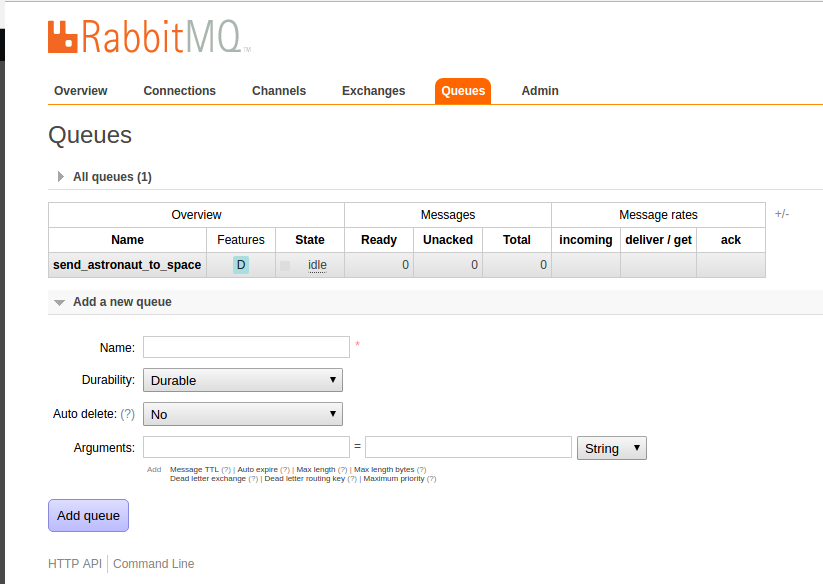
Now click on the Queues tab: send_astronaut_to_space is also here.
Let's take a look at the publication and consumption of messages.
The library helping us to consume and publish messages, Swarrot, has a Symfony bundle which will help us use it very easily in our app: SwarrotBundle.
The thing we want to achieve here is to publish messages, and to consume them. Here is how it's done.
After installing the bundle, we have to configure it:
# app/config/config.yml swarrot: provider: pecl # pecl or amqp_lib connections: rabbitmq: host: '%rabbitmq_host%' port: '%rabbitmq_port%' login: '%rabbitmq_login%' password: '%rabbitmq_password%' vhost: '/' consumers: send_astronaut_to_space: # name of the consumer processor: processor.send_astronaut_to_space # name of the service extras: poll_interval: 500000 requeue_on_error: false middleware_stack: - configurator: swarrot.processor.exception_catcher - configurator: swarrot.processor.ack
This is a configuration example. The interesting part comes around the "consumers" parameter.
Every message published in an exchange will be routed to a queue according to its routing jey. Therefore, we need to process a message stored in a queue. Using Swarrot, special things called processors are in charge of this.
To consume a message, we need to create our own processor. As indicated in the documentation, a processor is just a Symfony service who needs to implement the ProcessInterface interface.
The particularity of processors is that they work using middlewares, allowing to add behavior before and/or after the processing of our message (our processor). That's why there is a middleware_stack parameter, that holds two things: swarrot.processor.exception_catcher and swarrot.processor.ack. Although optional, these middlewares bring nice flexibility. We'll come back on this later on.
<?php
namespace AppBundle\Processor;
use Swarrot\Broker\Message;
use Swarrot\Processor\ProcessorInterface;
class SendAstronautToSpace implements ProcessorInterface
{
public function process(Message $message, array $options)
{
//...
}
}Our SendAstronautToSpace processor implements a method called process, which allows us to retrieve the message to consume, and use it in our application.
We've just setup the consumption of messages. What do we need to do next? See the publication part of course!
Once again, it's very simple to publish messages with Swarrot. We only need to declare a publisher in our configuration, and use the SwarrotBundle publication service to publish a new message.
# app/config/config.yml consumers: # ... middleware_stack: - configurator: swarrot.processor.exception_catcher - configurator: swarrot.processor.ack messages_types: send_astronaut_to_space_publisher: connection: rabbitmq exchange: default routing_key: send_astronaut_to_space
The secret is to declare a new message type, specifying the connection, exchange, and the routing key. Then publish a message this way:
<?php $message = new Message('Wilson wants to go to space'); $this->get('swarrot.publisher')->publish('send_astronaut_to_space_publisher', $message);
The service swarrot.publisher deals with publishing our message. Simple right?
After setting up queues, published and consumed a message, we now have a good view of the life-cycle of a message.
One last aspect I'd like to share with you today is about errors while consuming your messages.
Setting aside implementation problems in your code, it's possible that you encounter exceptions, due to external causes. For instance, you have a processor that makes HTTP calls to an outside service. The said service can be temporarily down, or returning an error. You need to publish a message and make sure that this one is not lost. Wouldn't it be great to publish this message again if the service does not respond? And do so after a certain amount of time?
Somewhere along the way, I've been confronted to this problem. We knew such things could happen and we needed to automatically "retry" our messages publication. I'm going to show you how to proceed, keeping our example send_astronaut_to_space. Let's decide that we're going to retry the publication of our message 3 times maximum. To do that, we need 3 retry queues. Fortunately, configuration of retry queues and exchanges is so easy with RabbitMQ Admin Toolkit: we only need one line! Let's see this more closely :
# default_vhost.yml # ... queues: send_astronaut_to_space: durable: true retries: [5, 25, 100] # Create a retry exchange with 3 retry queues prefixed with send_astronaut_to_space bindings: - exchange: default routing_key: send_astronaut_to_space
The array of parameters of key retries corresponds to the delay after which the message will be published again. Following the first failure, 5 seconds will go by before publishing again the message. Then 25 seconds, and finally 100. The behavior suits our problem perfectly...
If we launch our command one more time, here is the result:
vendor/bin/rabbit vhost:mapping:create default_vhost.yml --host=127.0.0.1 Password? With DL: false With Unroutable: false Create exchange default Create exchange dl Create queue send_astronaut_to_space Create queue send_astronaut_to_space_dl Create binding between exchange dl and queue send_astronaut_to_space_dl (with routing_key: send_astronaut_to_space) Create queue send_astronaut_to_space_retry_1 Create binding between exchange retry and queue send_astronaut_to_space_retry_1 (with routing_key: send_astronaut_to_space_retry_1) Create queue send_astronaut_to_space_retry_2 Create binding between exchange retry and queue send_astronaut_to_space_retry_2 (with routing_key: send_astronaut_to_space_retry_2) Create queue send_astronaut_to_space_retry_3 Create binding between exchange retry and queue send_astronaut_to_space_retry_3 (with routing_key: send_astronaut_to_space_retry_3) Create binding between exchange default and queue send_astronaut_to_space (with routing_key: send_astronaut_to_space)
We still create a default exchange. Then, many things are done:
Now let's configure our consumer.
With Swarrot, handling of retries is very easy to configure. Do you remember those middlewares we've seen before? Well there's a middleware for that!
# app/config/config.yml consumers: # ... middleware_stack: - configurator: swarrot.processor.exception_catcher - configurator: swarrot.processor.ack - configurator: swarrot.processor.retry extras: retry_exchange: 'retry' retry_attempts: 3 retry_routing_key_pattern: 'send_astronaut_to_space_retry_%%attempt%%' messages_types: send_astronaut_to_space_publisher: connection: rabbitmq exchange: default routing_key: send_astronaut_to_space
The main difference with our previous configuration is located around the parameter middleware_stack: we need to add the processor swarrot.processor.retry, with its retry strategy:
The workflow works this way: if the message is not acknowledged followingan exception the first time, it will be published in the retry exchange_,_ with routing key_send_astronaut_to_space_retry_1._ Then, 5 seconds later, the message is published back in our main queue send_astronaut_to_space. If another error is encountered, it will be republished in the retry exchange, with the routing key send_astronaut_to_space_retry_2, and 25 seconds later the message will be back on our main queue. Same thing one last time with 100 seconds.
bin/console swarrot:consume:send_astronaut_to_space send_astronaut_to_space
[2017-01-12 12:53:41] app.WARNING: [Retry] An exception occurred. Republish message for the 1 times (key: send_astronaut_to_space_retry_1) {"swarrot_processor":"retry","exception":"[object] (Exception(code: 0): An error occurred while consuming hello at /home/gus/dev/swarrot/src/AppBundle/Processor/SendAstronautToSpace.php:12)"}
[2017-01-12 12:53:46] app.WARNING: [Retry] An exception occurred. Republish message for the 2 times (key: send_astronaut_to_space_retry_2) {"swarrot_processor":"retry","exception":"[object] (Exception(code: 0): An error occurred while consuming hello at /home/gus/dev/swarrot/src/AppBundle/Processor/SendAstronautToSpace.php:12)"}
[2017-01-12 12:54:11] app.WARNING: [Retry] An exception occurred. Republish message for the 3 times (key: send_astronaut_to_space_retry_3) {"swarrot_processor":"retry","exception":"[object] (Exception(code: 0): An error occurred while consuming hello at /home/gus/dev/swarrot/src/AppBundle/Processor/SendAstronautToSpace.php:12)"}
[2017-01-12 12:55:51] app.WARNING: [Retry] Stop attempting to process message after 4 attempts {"swarrot_processor":"retry"}
[2017-01-12 12:55:51] app.ERROR: [Ack] An exception occurred. Message #4 has been nack'ed. {"swarrot_processor":"ack","exception":"[object] (Exception(code: 0): An error occurred while consuming hello at /home/gus/dev/swarrot/src/AppBundle/Processor/SendAstronautToSpace.php:12)"}
[2017-01-12 12:55:51] app.ERROR: [ExceptionCatcher] An exception occurred. This exception has been caught. {"swarrot_processor":"exception","exception":"[object] (Exception(code: 0): An error occurred while consuming hello at /home/gus/dev/swarrot/src/AppBundle/Processor/SendAstronautToSpace.php:12)"}When creating our virtual host, we saw that an exchange called dl , associated to a queue send_astronaut_to_space_dl has been created. This queue is our message's last stop if the retry mechanism is not able to successfully publish our message (an error is still encountered after each retry). If we look closely the details of queue send_astronaut_to_space, we see that "x-dead-letter-exchange" is equal to"dl", and that "x-dead-letter-routing-key" is equal to "send_astronaut_to_space", corresponding to our binding explained previously.
On every error in our processor, the retryProcessor will catch this error, and republish our message in the retry queue as many times as we've configured it. Then Swarrot will hand everything to RabbitMQ to route our message to the queue queue send_astronaut_to_space_dl.
Swarrot is a library that allows us to consume and publish messages in a very simple manner. Its system of middlewares increases possibility in the consumption of messages. Tied to RabbitMQ Admin Toolkit to configure exchanges and queues, Swarrot will also let you retry your lost messages very easily.
Author(s)
Romain Pierlot
Diplomé de l'ISEP en 2013, Romain Pierlot est ingénieur en Etudes et Développement chez Eleven Labs, avec qui il s'amuse comme un petit fou.
You wanna know more about something in particular?
Let's plan a meeting!
Our experts answer all your questions.
Contact usDiscover other content about the same topic
You work with Symfony, but the concept of dependency injection is a little blurry for you? Find out how to take advantage of the component reading this article.

Are you suffering from domain anemia? Let's look at what an anemic domain model is and how things can change.
How to deploy PHP applications to AWS Lambda with Bref