
Installer et configurer Caddy 2 avec certificat SSL pour tous vos sous-domaines
Sécuriser votre serveur avec des certificat SSL pour tous vos sous-domaines grâce au DNS challenge

![]()
Quand on arrive sur un projet existant, on doit souvent subir une dette technique qui nous fait perdre du temps et qui nous rend fou au point de vérifier qui a fait le code. Vous aussi vous voulez entrer dans la postérité lors d’un git blame et mal concevoir votre produit ?
Vous avez de la chance, j’ai pu voir quelques exemples qui vont me permettre de vous expliquer les meilleures techniques pour créer votre propre projet legacy 🥳
D’après Wikipédia, il s’agit d’un concept de développement logiciel qui désigne la difficulté à faire évoluer ou à corriger un code source mal conçu initialement.
Inventé en 1992, le terme vient d'une métaphore qui applique au développement la notion de dettes que l’on peut trouver dans le milieu de la finance. On peut dire qu’une équipe de développement contracte une dette pour acquérir plus rapidement une fonction.
Il est possible de contracter une dette consciemment pour des problématiques de délais, mais elle peut être prise inconsciemment.

Prendre des mauvaises décisions dès le début en faisant des erreurs d’architecture peut être de vrais boulets pour la vie du projet.
Il faut bien comprendre le besoin et vos contraintes car chaque type d’architecture à ses avantages et ses inconvénients (oui le monolithe a des avantages, et vous pouvez voir les avantages du micro-services dans l’article “D'un monolithe vers une architecture microservices”). Partir sur une architecture micro-services alors qu’il n’y a pas les ressources suffisantes niveau infrastructure ou dans les équipes de développements, c’est le début de la souffrance sur le projet.
Vous n’avez pas forcément d’architecte dans vos équipes, mais avec l’expérience et l’entraide, vous pouvez prendre en compte tous les besoins et imaginer l’architecture qu’il vous faut. Si vous avez un architecte sous la main, n’hésitez pas à collaborer avec lui : vous allez pouvoir être sûr qu’il a toutes les informations nécessaires et vous, vous allez apprendre à son contact !
Pour être sûr de ne pas oublier des possibilités, essayez de faire plusieurs architectures différentes pour les comparer.
Ensuite il y a le choix des technologies, langages et outils.
L’erreur principal dont les motivations sont diverses c’est de vouloir utiliser une technologie qu’on ne connaît pas. Par tendance, pour apprendre une nouvelle technologie, pour essayer de répondre à un besoin, peu importe votre raison, vous mettez le pied dans l’inconnu. Inconnu de temps, de montée en compétence, de maintenance, de coût et si cela répond réellement au besoin.
Les bonnes questions à vous poser sont :
On veut souvent tester les dernières tendances, mais si vous n’avez pas au moins 3 “Oui” à la liste de questions, revoyez votre copie.
Même si le modèle est criticable, vous pouvez aussi vous baser sur le cycle de la hype : il est plus raisonnable de prendre une technologie quand elle est à son plateau de productivité.
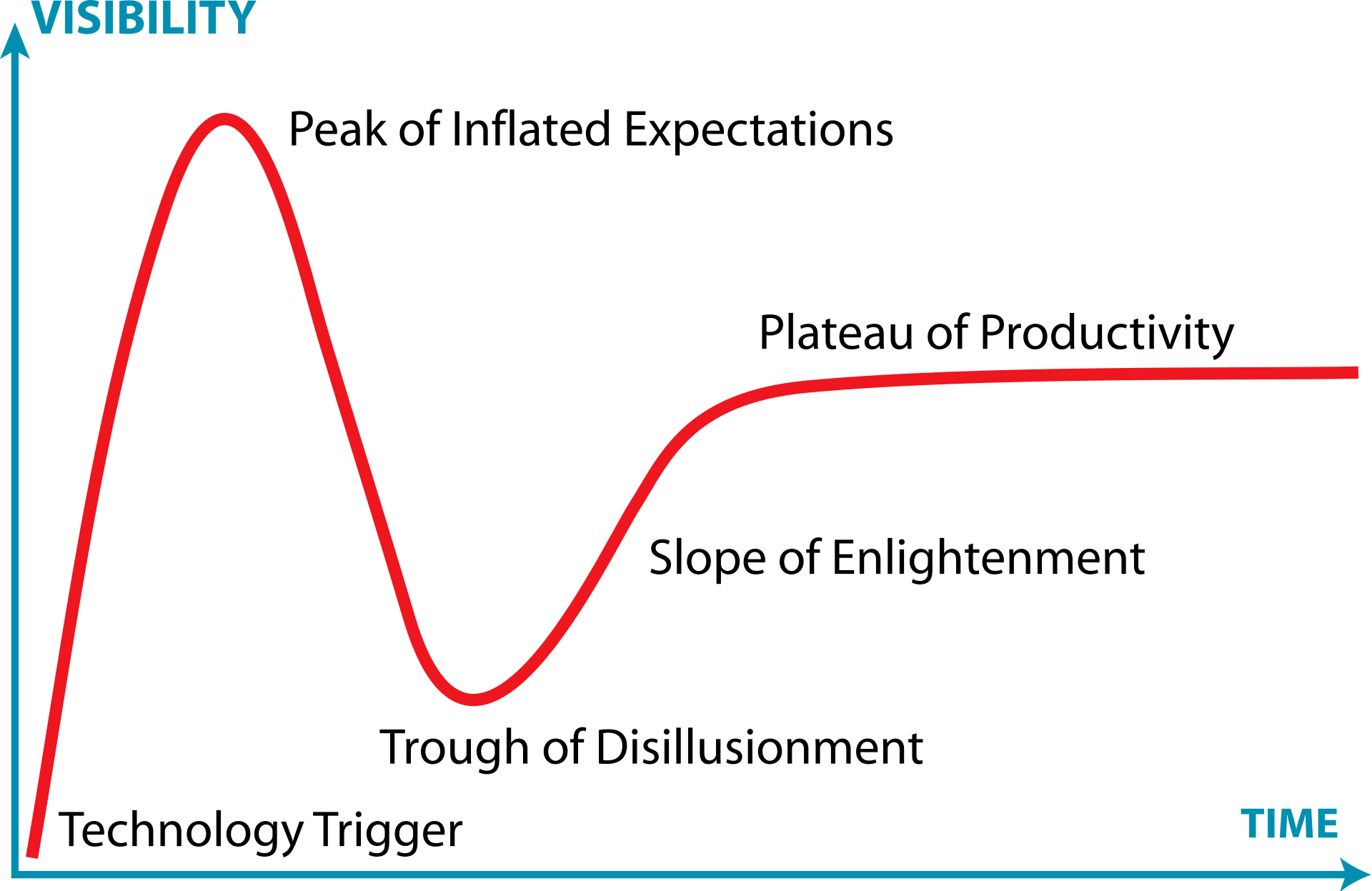

Point critique qui peut être source de problème de performances sur des applications qui ont besoin d’être rapide à lire en écriture et/ou en lecture. S’il y a trop de latence, un client peut délaisser votre produit pour un concurrent.
Je vais m’attarder sur les bases de données orientées objets et celles orientées documents, et certains conseils sont valables pour les deux.
Le conseil principal est de prendre le temps de modéliser votre base de données. C’est une pratique qui se perd mais qui pourtant permet de prendre de la hauteur sur le besoin et de détecter de potentielles trous dans la raquette pour répondre au mieux aux attentes.
J’ai un petit faible pour modéliser en UML et j’utilise PlantUML (qui possède un plugin sur PhpStorm) pour modéliser facilement et comme c’est du scripting, on peut même le versionner dans git.
Pour la base de données orientée objets, on a souvent l’habitude d’utiliser le modèle relationnel, et c’est ce que je vous recommande dans les cas les plus courants.
Mais il existe un modèle de données appelé Entity–attribute–value model qu’on oublie un peu trop souvent : il s’agit d’un grosso-modo de faire une table en plus de sa table entity contenant la liste de clé-valeur. J’ai eu l’occasion de l’utiliser dans un des cas où beaucoup de champs ne sont pas obligatoires pour éviter d’avoir une table entity beaucoup trop grosse. Elle comporte quelques faiblesses comme l’efficacité du requêtage (bref, ne faîte pas de recherche dessus), on ne peut pas être sûr que les clés soient toutes bien orthographiées, on ne peut pas typé la valeur etc…
Je vous en parle car cela peut totalement convenir à certains cas d’utilisation comme la construction de générateur à formulaires.
Pour la base de données orientée documents, il faut aussi prendre le temps de la modélisation. Pour rappel, vous pouvez voir la définition d’une base de données documents avec MongoDB sur l’article Symfony et MongoDB, retour aux bases.
Quand on a connu le modèle relationnel, il faut changer sa pensée pour comprendre le document et son modèle. Je vous conseille cette vidéo qui permet de comprendre ce changement de modélisation : Base de données : MongoDB - Conception par Algomius.
Je pense que la plus grosse erreur que j’ai pu voir, c’est de tout mettre dans une même collection. Une collection un peu fourre-tout car la technologie le permet. Mais la gestion des indexes étant plus compliquée mais aussi plus importante dans ce type de base de données, cette modélisation coûtera très cher à maintenir dans le temps.
A contrario d'une base de données SQL et de ses jointures, une modélisation NoSQL se veut la plus proche de son utilisation/consommation, comme dans une approche API First par exemple : la donnée doit être modélisée comme elle sera consommée.
Quoi qu’il arrive, n’oubliez pas votre besoin : performance lecture ou écriture, recherche, comment votre application va utiliser vos données…
Je vais un peu enfoncer des portes ouvertes, mais pour un minimum assurer une qualité de code, il faut connaître et appliquer quelques principes, et à minima SOLID.
Les autres principes du Clean Code comme YAGNI (You Ain't Gonna Need It), DRY (Don’t Repeat Yourself) ou KISS (Keep It Simple, Stupid) sont aussi conseillés pour avoir un code compréhensible, intuitif et facile à modifier.
Cela vous aidera aussi à éviter de faire de l’over-engineering : faire du code ayant inutilement compliqué ou élaboré alors qu’un code plus simple peut répondre au besoin.
Les commentaires sur des MRs pourront vous aider à vous améliorer, vous indiquer des fonctions ou des façons de faire pour être au plus proche des bonnes pratiques.
On ne rappellera jamais assez les bienfaits des tests automatisés : on évite les bugs, on améliore la qualité logicielle, ça permet de faire gagner du temps même si pour cela, il faut en investir !
Il y a plusieurs articles sur le blog vous donnant les définitions de tests unitaires, fonctionnels, intégrations, end-to-ends avec différents outils pour revoir les bases :
Mais ça ne répond pas à la question : quelle est la différence entre un mauvais test et un bon test ?
Voici quelques questions à vous poser :
N’oubliez pas que les tests sont aussi là pour vous aider même si c’est barbant de les faire !
Maintenant, vous avez quelques clés pour éviter de faire de la dette technique dès le début d’un projet ! Avec votre expérience, souvenez-vous de ce code imbitable qui vous a donné des cauchemars, et rappelez-vous de tout ça pour éviter de refaire les mêmes erreurs.
Car comme le disait Albert Einstein :
La folie, c'est de faire toujours la même chose et de s'attendre à un résultat différent
Auteur(s)
Vous souhaitez en savoir plus sur le sujet ?
Organisons un échange !
Notre équipe d'experts répond à toutes vos questions.
Nous contacterDécouvrez nos autres contenus dans le même thème
Sécuriser votre serveur avec des certificat SSL pour tous vos sous-domaines grâce au DNS challenge

Ce guide présente Apache Iceberg, un format de table moderne pour les données volumineuses, la gestion des versions et des performances optimisées.

Découvrez comment créer un serveur MCP en TypeScript à l'aide du SDK officiel. Apprenez à fournir un contexte riche aux LLMs.