RabbitMQ est un message broker très complet et robuste, c'est pourquoi le comprendre et l'utiliser est assez simple. en revanche, le maîtriser l'est un peu moins...
C'est pourquoi je vous propose cette série de deux articles. Vous pouvez retrouver la partie 2 en cliquant ici.
Bref, pour commencer, avant de manger du pâté de lapin il va falloir bouffer des carottes !
Introduction
RabbitMQ a de nombreux points forts, ce qui en fait une solution utilisable sur tous types/tailles de projet.
En voici quelques-uns :
- Utilise AMQP (courante: 0.9.1)
- Développé en
Erlang ce qui en fait un logiciel très robuste
- Système de clustering pour la haute disponibilité et la scalabilité
- Un système de plugins qui permet d'apporter d'autre fonctionnalités (management, ldap, shovel, mqtt, stomp, tracing, AMQP 1.0)
- Les vhost permettent de cloisonner des environnements (mutualiser le serveur, env dev/preprod/prod)
- Quality Of Service (QOS) permet de prioriser les messages
AMQP
Ok, donc on va commencer par semer des carottes
Afin de pouvoir utiliser efficacement RabbitMQ il faut comprendre le fonctionnement du protocol AMQP.
Le Broker
RabbitMQ est un message broker, son rôle est de transporter et router les messages depuis les publishers vers les consumers.
Le broker utilise les exchanges et bindings pour savoir si il doit délivrer, ou non, le message dans la queue.
Voici le fonctionnement global du broker :
Le publisher va envoyer un message dans un exchange qui va, en fonction du binding, router le message vers la ou les queues.
Ensuite un consumer va consommer les messages.
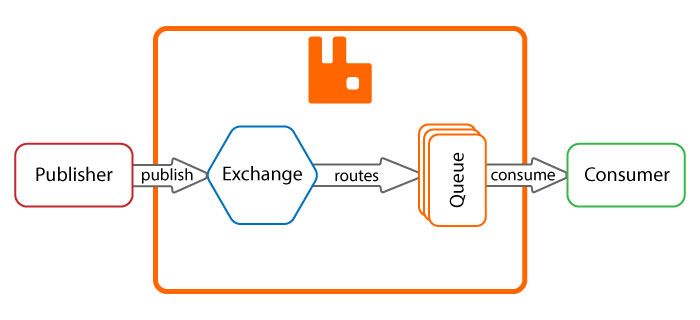
Nous allons donc détailler les différents éléments qui composent le broker.
Le message
Le message est comme une requête HTTP, il contient des attributs ainsi qu'un payload.
Parmi les attributs du protocol vous pouvez y ajouter des headers depuis votre publisher.
Liste des properties du protocol
content_type, content_encoding, priority, correlation_id, reply_to, expiration, message_id, timestamp, type, user_id, app_id, cluster_id
Les headers seront disponibles dans attributes[headers].
L'attribut routing_key, bien qu'optionnel, n'en est pas moins très utile dans le protocol.
Les Bindings
Les bindings, ce sont les règles que les exchanges utilisent pour déterminer à quelle queue il faut délivrer le message.
Les différentes configurations peuvent utiliser la routing key (direct/topic exchanges) ainsi que les headers(header exchanges).
Dans le cas des exchanges fanout, les queues n'ont qu'à être bindées pour recevoir le message.
Nous allons détailler leurs utilisations.
Les Exchanges
Un exchange est un routeur de message. Il existe différents types de routages définis par le type d'exchange.
Vous publiez dans un exchange. Vous ne consommez pas un exchange !
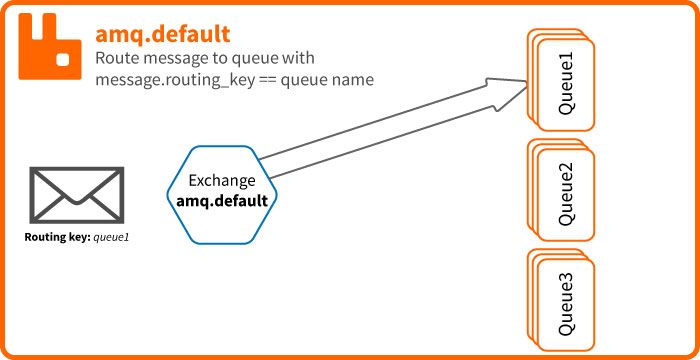
Important à savoir : l'exchange amq.default est l'exchange par défaut de rabbit. Vous ne pouvez ni le supprimer ni vous binder dessus.
Cet exchange est auto bindé avec toutes les queues avec une routing key égale au nom de la queue.
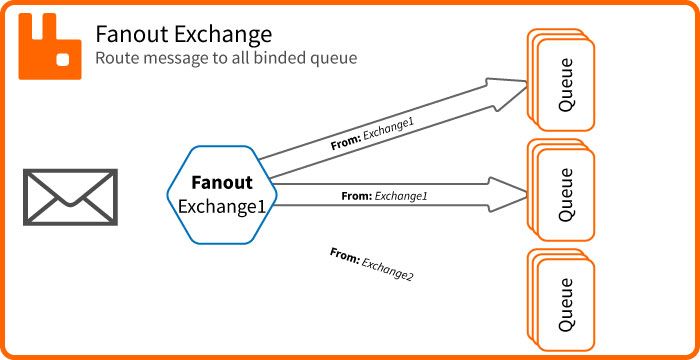
L'exchange type fanout
L'exchange fanout est le plus simple. En effet il délivre le message à toutes les queues bindées.
L'exchange type direct
L'exchange direct n'autorise que le binding utilisant strictement la routing key.
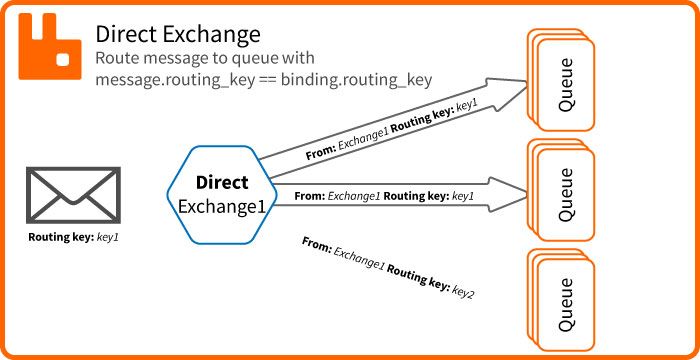
Si la routing_key du message est strictement égale à la routing_key spécifiée dans le binding alors le message sera délivré à la queue.
binding.routing_key == message.routing_key
L'exchange type topic
L'exchange topic délivre le message si routing_key du message matche le pattern défini dans le binding.
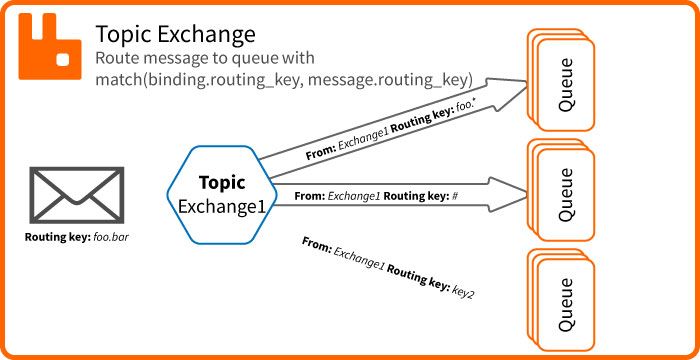
Une routing key est composé de plusieurs segments séparés par des .. Il y a également 2 caractères utilisés dans le matching.
* n'importe quelle valeur de segment
# n'importe quelle valeur de segment une ou plusieurs fois
Par exemple pour la routing key foo.bar.baz
foo.*.baz matchfoo.*.* matchfoo.# matchfoo.#.baz match*.*.baz match#.baz match#.bar.baz match# matchfoo.* non trouvé
match(binding.routing_key, message.routing_key)
L'exchange headers délivre le message si les headers du binding matchent les headers du message.
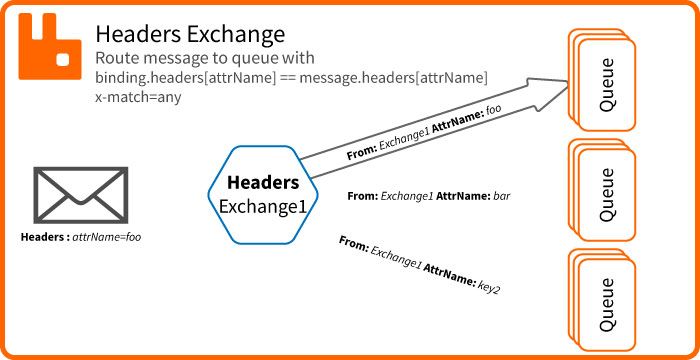
L'option x-match dans le binding permet de définir si un seul header ou tous doivent matcher.
x-match = any
Avec le x-match = any le message sera délivré si un seul des headers du binding correspond à un header du message.
binding.headers[attrName1] == message.headers[attrName1] OU binding.headers[attrName2] == message.headers[attrName2]
Le message sera délivré si le header attrName1 (configuré au moment du binding) est égal au header attrName1 du message
OU
si le header attrName2 est égal au header attrName2 du message.
x-match = all
Avec le x-match = all le message sera délivré si tous les headers du binding correspondent aux headers du message.
binding.headers[attrName1] == message.headers[attrName1] ET binding.headers[attrName2] == message.headers[attrName2]
Ici le message sera délivré seulement si les headers attrName1 ET attrName2 (du binding) sont égaux aux headers attrName1 et attrName2 du message.
Les Queues
Une queue est l'endroit où sont stockés les messages. Il existe des options de configuration afin de modifier leurs comportements.
Quelques options :
- Durable, (stockée sur disque) la queue survivra au redémarrage du broker. Attention seuls les messages persistants survivront au redémarrage.
- Exclusive, sera utilisable sur une seule connexion et sera supprimée à la clôture de celle-ci.
- Auto-delete, la queue sera supprimée quand toutes les connections sont fermées (après au moins une connexion).
Vous publiez dans un exchange. Vous ne consommez pas un exchange !
(quand vous croyez publier dans une queue en réalité le message est publié dans l'exchange amq.default avec la routing key = queue name)
Consumer
Le rôle du consumer est d'exécuter un traitement après avoir récupéré un ou plusieurs messages.
Pour ce faire il va réserver (prefetching) un ou plusieurs messages depuis la queue, avant d'exécuter un traitement.
Généralement si le traitement s'est correctement déroulé le consumer va acquitter le message avec succès (basic.ack).
En cas d'erreur le consumer peut également acquitter négativement le message (basic.nack).
Si le message n'est pas acquitté, il restera à sa place dans la queue et sera re fetch un peu plus tard.
Vous voila maintenant fin prêts à récolter vos carottes !
Vous pouvez maintenant consulter la partie 2 (maîtrise), dans laquelle nous verrons comment attraper les lapins, et comment préparer le pâté. 😜
Liens utiles
http://www.rabbitmq.com/documentation.html


