Les policies, le retry (dead letter, poison message)... en avant pour l'utilisation avancée de RabbitMQ.
Introduction
Après avoir vu les bases dans RabbitMQ : Les bases (Partie 1),
nous allons pousser un peu plus loin l'utilisation de RabbitMQ.
Plugins
🥕 Les plugins sont comme des engrais pour votre champ de carottes.
Je vous invite à consulter la page des plugins ainsi que le Github
afin de voir les plugins officiels disponibles.
D'autre part je vous conseille fortement d'activer au minimum les plugins suivants :
rabbitmq_management ce plugin ajoute une interface web très pratique pour configurer RabbitMQ.rabbitmq_tracing ce plugin (dans l'onglet Admin > Tracing) vous permet de tracer (debug) les messages.
Authentification / Autorisation
Dans tout système d'informations, l'utilisation de permissions, par utilisateur/groupe, est une notion très importante.
Elle permet d'organiser et maîtriser l'utilisation et l'accès au service.
RabbitMQ embarque un système interne d'authentification/autorisation mais une fois de plus il existe différents plugins d'auth.
ℹ️ Avec le plugin rabbitmq-auth-backend-http vous pouvez même
déléguer cette partie à une API HTTP (Les utilisateurs de votre plateforme sont connectés à RabbitMQ ! 😜).
Voici une implémentation en PHP qui utilise le composant security de Symfony.
Vous avez même la possibilité de configurer plusieurs systèmes d'auth en cascade.
auth_backends.my_auth_1 = internal
auth_backends.my_auth_2 = http
...
Ici les valeurs my_auth_1 et my_auth_2 sont arbitraires et peuvent prendre n'importe quelle valeur.
Utilisateur
Un utilisateur (username, password facultatif) est utilisé pour se connecter à RabbitMQ afin de publier et consommer les messages.
Le plugin rabbitmq_management ajoute une notion de tags (administrator, monitoring, policymaker, management, impersonator)
afin de limiter l'accès aux différentes parties de l'interface.
Une fois votre utilisateur créé, il faudra lui ajouter des permissions sur chaque vhost auxquels il aura accès.
Sur le backend d'auth par défaut (rabbit_auth_backend_internal), les permissions sont séparées en 3 groupes :
- Configure regexp
- Write regexp
- Read regexp
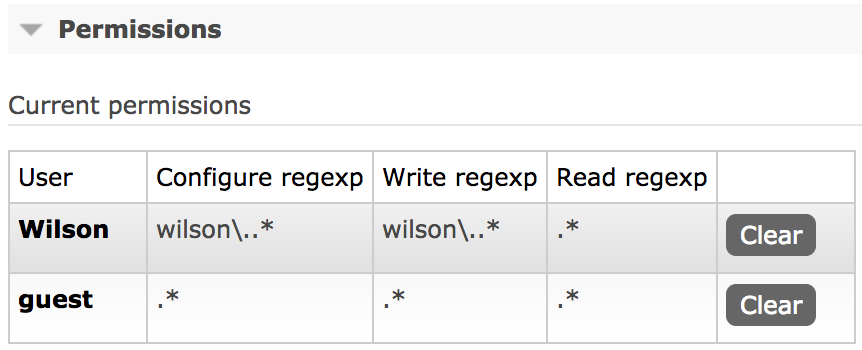
🚀 Pour une utilisation plus simple des regexp je vous conseille d'avoir une vraie stratégie de nommage des exchanges/queues
avec des préfixes/segments/suffixes. D'une part vous pourrez plus facilement identifier qui a créé les ressources mais aussi qui les consomme.
Je vous laisse consulter le tableau de répartition des actions par ressource
🥕 Maintenant vous pouvez facilement identifier vos petits lapins.
Policies
Les policies sont des règles de configurations qui s'appliquent aux exchanges et aux queues (dont le nom matche une regexp) afin de diminuer la redondance de configuration mais aussi et surtout de pouvoir changer une policy sans avoir à détruire et recréer la ressource (exchange/queue).
Certaines options de configuration d'une policy sont spécifiques aux exchanges et d'autres aux queues.
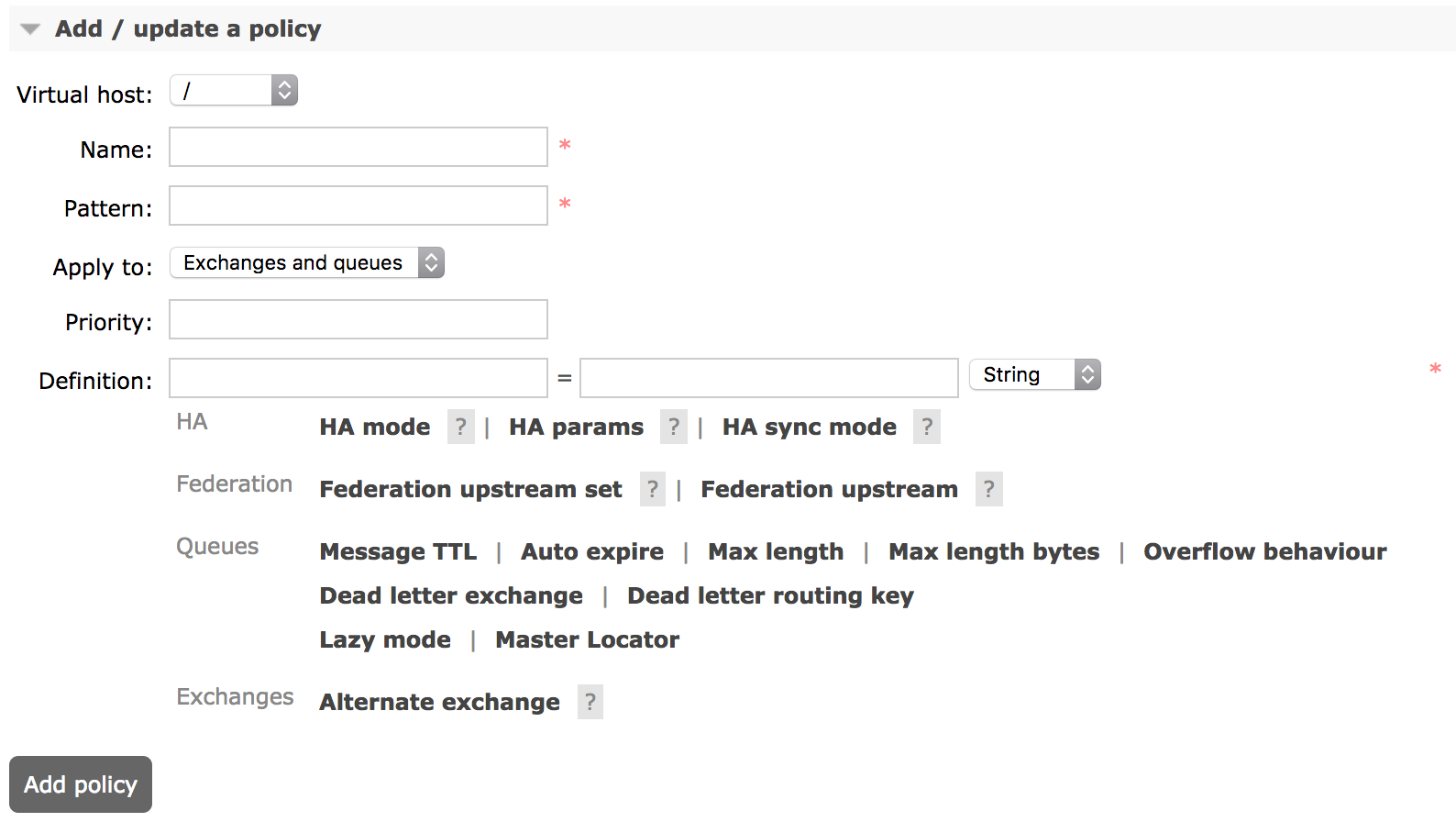
Les Policies peuvent être utilisées pour configurer :
⚠️ Attention, l'utilisation de policies peut devenir rapidement complexe.
Retry (Dead letter)
Les retries sont un autre sujet très important de RabbitMQ ! Quand le message consumer rencontre une erreur durant le traitement d'un message il peut être intéressant dans certains cas de réessayer le traitement du message.
Les différentes solutions sont :
- Ne pas ACK ou NACK le message (Retry infini instantané bloquant)
Le message va garder sa place dans la queue et le consumer va de nouveau récupérer ce message au prochain get.
⚠️ Je déconseille très fortement cette approche ! Car le consumer va toujours récupérer le même message jusqu'au succès du traitement,
qui pourrait ne jamais se produire et créer une boucle infinie. De plus le message en erreur bloque le dépilement des messages suivants.
- NACK le message avec une queue configurée avec DLX = "" (default exchange amq.default) et DLK = {QUEUENAME} (Retry infini instantané non bloquant)
Le message va être remis en début de queue.
⚠️ Je déconseille également cette approche ! Cette fois-ci, le message ne va pas bloquer le dépilement des autres messages de la queue,
mais il peut quand même créer une boucle infinie si il n'y a qu'un message dans la queue.
- ACK le message après avoir publié un clone du message depuis le consumer. (Solution la plus dynamique -> retry retardé variable non bloquant)
ℹ️ Avec cette solution on peut facilement gérer des "délais avant retry" variables. Premier retry à 5 secondes, deuxième à 10 secondes, etc...
⚠️ Je garde une réserve sur cette pratique car elle fonctionne mais positionne la responsabilité du retry du côté applicatif.
- NACK le message avec un délai avant de retry le message (Le "délai avant retry" est fixe -> retry retardé fix non bloquant)
👍 Le message va être remis en début de queue après avoir été mis en attente pendant un temps défini.
C'est cette dernière solution que nous allons détailler.
Pour mettre en place cette solution nous allons devoir créer un exchange et une queue d'attente.
Créer un exchange qui va router les messages dans la queue d'attente waiting_5 type fanout.
Créer une queue d'attente waiting_5 avec x-dead-letter-exchange: "" et x-message-ttl: 5000.
Puis binder cette queue sur l'exchange waiting_5.
⚠️ le x-dead-letter-exchange doit être configuré avec une chaîne vide (amq.default).
Configurez ensuite votre queue queue1 avec x-dead-letter-exchange: "waiting_5" x-dead-letter-routing-key: queue1.
⚠️ le x-dead-letter-routing-key doit être configuré avec le nom de la queue.
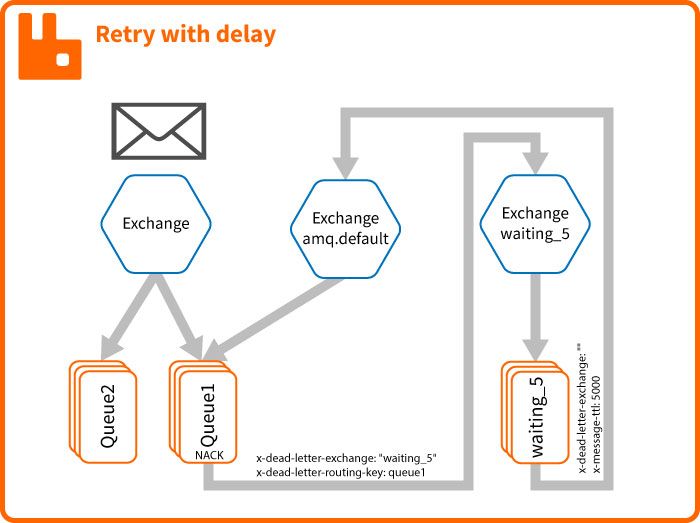
Avec cette configuration, quand le consumer NACK le message, RabbitMQ redirige le message dans l'exchange waiting_5 (fanout)
qui va donc router ce message dans la queue waiting_5. La queue waiting_5 va attendre 5 secondes avant d'expired le message,
il va donc arriver dans l'exchange amq.default avec comme routing key queue1 et donc être routé dans la queue queue1.
ℹ️ À noter que le retry est infini. Ce qui peu également créer des poison messages.
Poison message
Un poison message c'est un message que le consumer rejettera (NACK) à chaque fois qu'il va le consommer.
Afin de traiter les poisons messages il faut que le consumer regarde dans les properties du message afin de vérifier
que le nombre de tentatives n'a pas été atteint.
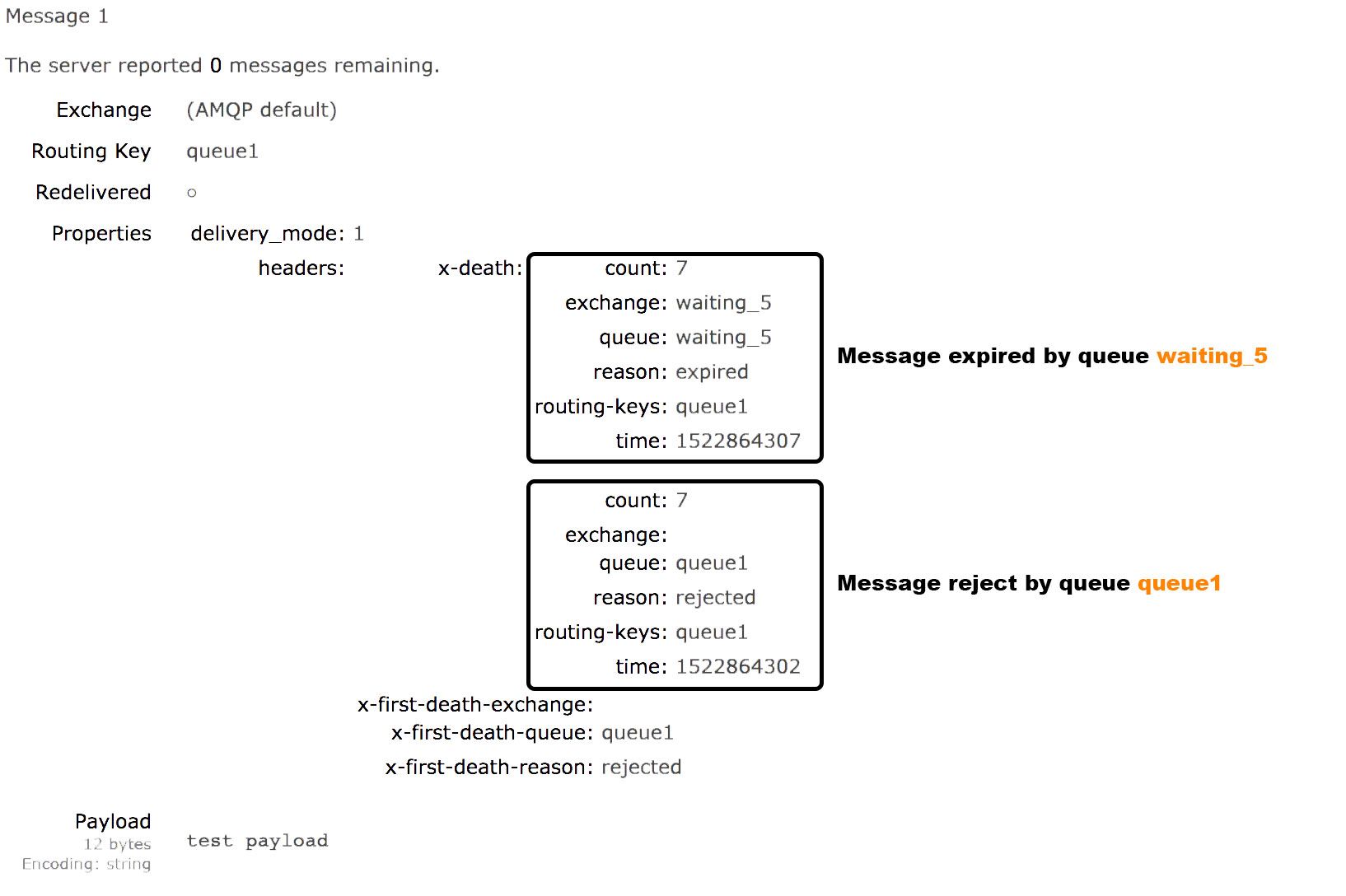
Si le nombre de retry a été atteint il faudra loguer une erreur et ACK le message.
Production
Consultez la documentation sur les recommandations pour les serveurs de production.
🐇 Vous voici maintenant fin prêt à déguster un bon pâté de lapin !
Liens utiles
https://www.rabbitmq.com/admin-guide.html


